曲がった迷路その39 - DFT効率の比較 [曲がった壁を持つ迷路の生成]
曲がった壁を持つ迷路生成のキモであるスペックルの計算にfftwライブラリを使っていたがあまりに巨大で釣り合いがとれない。そこで任意基数の離散Fourier変換(DFT)を独自実装することに決めた。
とりあえずDFTの定義式通りの計算をやることにした。迷路生成ではDFTは初期化にしか使わないのでこれで十分なパフォーマンスが得られればこれをそのまま使う。
前回はAppleのAccelerate frameworkのvDSPライブラリにある複素数配列のかけ算のルーチンを使ってDFTを書いてみた。
今日はそれらの実行速度をfftwと比較する。さて、使い物になるのか....
実行効率の比較
それでは実際に実行して速度を較べてみる。比較したのは2次元のDFTで
- fftw
- vDSPをつかったもの(かけ算足し算をvDSPで)
- C99複素数を使ってそのまま数式を展開したもの
- vDSPをNSOperationでMulti-thread化したもの
昔やったunixのtimes()システムコールを使って実行時間を比較した。ユーザタイムを比較すればいいんだけどそのときは、マルチコアではユーザタイムはコアの合計時間になるのでMulti threadにした効果が測れない。しかたがないので重いプロセスは走らないようにしておいて実経過時間で測定した。
DFTサイズを2のベキと、そのすぐ近くの素数を選んだ。 結果がこれ。gccは4.2.1 Appleビルドの5646で最適化オプションはXCodeのreleaseのデフォルトのまま。
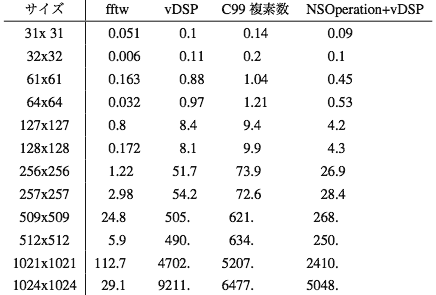
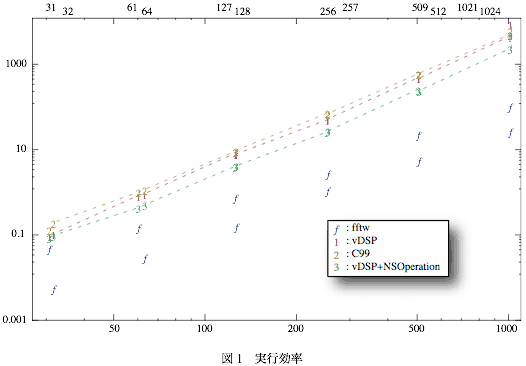
正方形のデータで比較したので縦横おなじことを繰り返すときに計算をはしょれる部分もある。そこで509×503というのをやってみたけどfftwとの差はまったく詰らなかった。
NSOperationを使ってMulti threadにした場合は2コアでほぼ半分の時間でできている、という結果なのでこれはまあ当たり前。
vDSPとC99複素数そのままとの比較は案外、差は小さかったという感じ。C99複素数もgccコンパイラがベクタユニットを使うコードを自動的に吐いているのでその効果なのか。
意外なのが1024×1024のとき。vDSPよりもC99複素数そのままの方が速くなって逆転した。2回繰り返したけど順番は入れ替わらなかった。vDSPにはなにかサイズ制限があるのかもしれない。
それにしてもfftwはすごい。ソースからコンパイルしてるんだから見ればいいんだけど、fftwのソースって巨大な上にすごく読みにくいしなあ。
結論
まとめると- やっぱりfftwは速い
- vDSPはたしかに速くなるけど式の通り書くのと較べて倍も速くならないくせに手間は何倍もかかる
- それとは無関係だけどNSOperationはちゃんとマルチコアを使いこなす
しかし
どうせDFTが律速しているわけではないので遅くてもいいや、と思っていたけど、512×512のDFTが2秒もかかるのはいまいち。ユーザインターフェイスとして「New...」メニューで大きさを決めてから、実際に作業の準備ができるまで待たされる時間が長いのはよくない。少なくとも1秒以内にレスポンスが欲しい。さすがにいくらなんでも二桁離されるのはなさけないだろう。
ということであともうちょっとだけがんばってみることにする。
2009-09-03 22:05
nice!(0)
コメント(1)
トラックバック(0)


沒有醫生的處方
cialis savings card http://cialisvipsale.com/ Cialis kaufen
by Buy cialis (2018-04-14 03:48)