パフォーマンス比較 [任意点数のFFT]
一昨日までで実装は一段落した。まったく最適化していないのでさくさくっ、とやってしまったが、筋道を整理するという意味ではこういうやり方の方が望ましい。
ということで、今回実装した生のままのアルゴリズムのパフォーマンスを比較してみる。
パフォーマンス比較
パフォーマンスの最適化はまったくしていないけど僕の経験によると、数値計算ではデバグが難しい場合(誰も正しい結果を知らないということがよくあるので)があるので「まず正しい答えを返す」ものを作ることを最優先することを心がけないといけない。最適化は十分動作が確認できてからでいい。またFFTの場合、アルゴリズムそのものによる効率化に較べてループをほぐしたりといった最適化は手間のわりに効果は薄い。FFTの最適化は面倒な時間を費やしてバグを呼び込んで、そのわりにたいして速くならない、という典型。最初にfftwとパフォーマンスを比較したのとどのくらい改善されたのか比較してみる。前回は2のベキと素数とで比較したが、混合基数も用意したので小さな素因数に分解できる場合も比較の対象にする。やりかたは前と同じだけど、面倒なので1次元のDFTにした。また、ひとつのthreadだけで走るようにして実時間ではなくプロセス時間で比較した。
任意のNでの比較
まずNが比較的小さい値のときの実行効率をlog-logプロットして比較したものを図-4に示す。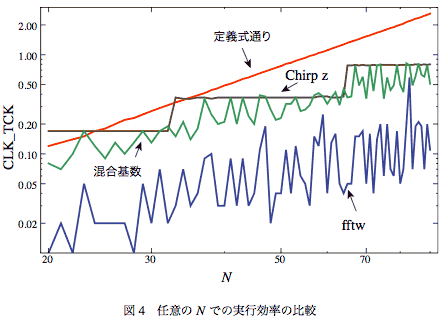
- 定義式通り
- 混合基数
- Chirp z変換
- fftw
一目見てわかるのはChirp z変換が2のベキのところでジャンプしていてそこ以外では平坦になっている。これはアルゴリズムからすれば当然。Chirp z変換はときどき定義式通りに負けてるけど、Nが25以下の場合と32の場合だけなので、かなり有効だということがわかる。
定義式通りはlog-logで直線になっているのでNのベキ乗に比例していることがわかる。これもあたりまえ。
混合基数は、素因数が大きな素数のときにはそのFFTにChirp zのインスタンスを使うようにしたので上限がChirp zの線に接している。もちろん接しているのはNが素数のところで、それよりも下にあるときは素因数分解によって計算量が減ったことに対応している。ちゃんとその通りになってて面白い。しかし、例えば24(=3×2×2×2)より25(=5×5)の方が速い。これなんでだろう?
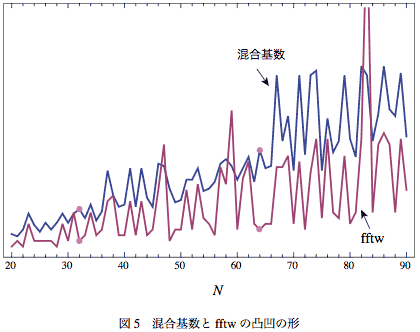
混合基数とfftwはNの値によって効率が上下している。このふたつを線形にプロットして図として並べてみたものが図-5である。縦軸を合わせるとほんとうは混合基数の方がずっと上にあるけど、わかりやすいように調整した。
2009-09-30 21:53
nice!(0)
コメント(0)
トラックバック(0)


コメント 0