ポリゴンレンダラ - その10 [プログラミング]
前回今回の計算にvDSPが使えるか、使えるとしたらどうすればいいか、を考えた。劇的に速くなる、ということはあまりなさそう、ということぐらいはわかった。ということで実際に測定してみよう。今回のようなパフォーマンスが問題になるアプリでは、vDSPが速いとAppleが言ってるから、というだけでそれに最適化したりせず、具体的に測定してみることが重要。
やってみると、ごく当たり前の結果と、思いもしなかった結果が得られた...
とりあえず同次座標変換を試してみる。これでvDSPのほうが速くなければ、他の例えばベクトルの内積なんかもvDSPを使ったとしても速くはならないはずである。
比較は
まず、ベクトルとマトリクスの型を定義する。
こういう明示的にサイズの決まった配列はコンパイラにとって最適化が一番やりやすい。おそらく効率的にベクタユニットを使うコードを吐くはずである。
ふつうにCで計算する場合、ベクトルの内積をまず定義して、結果のベクトルの要素はマトリクスの列ベクトルとかけ算されるベクトルとの内積として書くのがわかりやすい。つまり
かけるマトリクスはひとつで、かけ算されるベクトルがたくさんある、という同次変換のシチュエーションを考える。かけられるベクトルの配列とかけ算の結果を格納するベクトルの配列はまえもって確保しておく。
コンパイラはLLVM4.2で、最適化設定はXcode4.6.1のデフォルトReleaseセッティングのままにする。ハードウェアは2.7 GHz Intel Core i5のiMacでMacOS X10.8.3。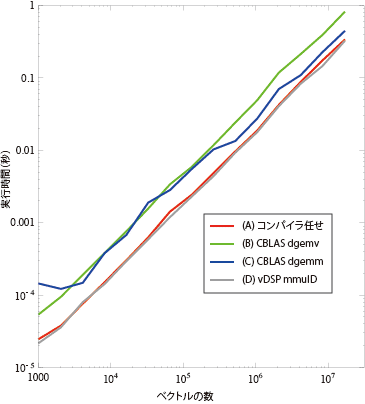 ほぼかけ算するベクトルの数に比例して計算時間が増えている。これは計算量は正確にベクトルの数に比例するから当たり前である。一番実行時間の短いのはvDSPだけど、コンパイラ任せにしてもvDSPに肉薄するぐらい速いことがわかる。
ほぼかけ算するベクトルの数に比例して計算時間が増えている。これは計算量は正確にベクトルの数に比例するから当たり前である。一番実行時間の短いのはvDSPだけど、コンパイラ任せにしてもvDSPに肉薄するぐらい速いことがわかる。
CBLASのマトリクスとベクトルのかけ算(cblas_dgemv)を繰り返したのが遅い(vDSPの2.5倍時間がかかっている)のはまあ当然としても、vDSPと同じやり方でマトリクスとマトリクスのかけ算(cblas_gemm)を使ったのもそれほど速くないのは意外だった。なんだ、CBLASだめじゃん、とここでは思った。
ところが、驚きの結果が。次回に続く....
やってみると、ごく当たり前の結果と、思いもしなかった結果が得られた...
7.4 vDSPの効率測定
ということでベクトルの単純計算にvDSPを使うことでどのくらい速くなるのか、確認しておこう。XcodeはデフォルトでLLVMを使うようになって、ますます最適化されたコードを出力するようになっているらしいので、比べよう。とりあえず同次座標変換を試してみる。これでvDSPのほうが速くなければ、他の例えばベクトルの内積なんかもvDSPを使ったとしても速くはならないはずである。
比較は
- ふつうにCで計算する
- CBLASを使う
- マトリクスとベクトルのかけ算を繰り返し使う
- マトリクスとマトリクスのかけ算を使う
- vDSPを使う
まず、ベクトルとマトリクスの型を定義する。
const int dimension = 4;
typedef double vector[dimension];
typedef struct matrixStruct {
vector r[dimension];
} matrix;
ベクトルは倍精度浮動小数点数が4つ並んでいる型で、マトリクスはそのベクトルがさらに4つ並んでいる型にする。こう定義すると、アラインメントによる空きはなくパック(密な)されて、ベクトルは32バイト、マトリクスは128バイトになる。こういう明示的にサイズの決まった配列はコンパイラにとって最適化が一番やりやすい。おそらく効率的にベクタユニットを使うコードを吐くはずである。
ふつうにCで計算する場合、ベクトルの内積をまず定義して、結果のベクトルの要素はマトリクスの列ベクトルとかけ算されるベクトルとの内積として書くのがわかりやすい。つまり
double innerProduct(vector *v1, vector *v2)
{
double ret = 0.0;
int i;
for (i = 0 ; i < dimension ; i ++)
ret += (*v1)[i] * (*v2)[i];
return ret;
}
void mvProduct(vector *result, matrix *m, vector *v)
{
int i;
for (i = 0 ; i < dimension ; i ++)
(*result)[i] = innerProduct(&(m->r[i]), v);
}
みたいな感じにする。関数呼び出しのオーバーヘッドは大きいけど、最終的に内積関数はコンパイラがインライン展開するだろう、との読みでこうしておく。かけるマトリクスはひとつで、かけ算されるベクトルがたくさんある、という同次変換のシチュエーションを考える。かけられるベクトルの配列とかけ算の結果を格納するベクトルの配列はまえもって確保しておく。
7.4.1 (A) コンパイラ任せ
普通に計算するということはfor (n = 0 ; n < num ; n ++) mvProduct(ret + n, &mat, vec + n);とするだけである。変数のnumというのはベクトルの個数である。場合によってはここまでインライン展開されるかもしれない。
コンパイラはLLVM4.2で、最適化設定はXcode4.6.1のデフォルトReleaseセッティングのままにする。ハードウェアは2.7 GHz Intel Core i5のiMacでMacOS X10.8.3。
7.4.2 (B) CBLASのマトリクスとベクトルのかけ算関数
つぎはCBLASのマトリクスとベクトルのかけ算を使ってfor (n = 0 ; n < num ; n ++) cblas_dgemv(CblasRowMajor, CblasNoTrans, dimension, dimension, 1.0, (double *)(mat.r), dimension, (double *)(vec + n), 1, 0.0, (double *)(ret + n), 1);つまり、さっき手で書いたマトリクスとベクトルの積をCBLASの関数を使ってやる。CBLASはマトリクスの転置なんかのオーバーヘッドが大きいので、これは実行効率的には厳しいはず。
7.4.3 (C) CBLASのマトリクスとマトリクスのかけ算関数
それからベクトルの配列をマトリクスとみなして、マトリクスとマトリクスのかけ算を使ってcblas_dgemm(CblasRowMajor, CblasNoTrans, CblasTrans, num, dimension, dimension, 1.0, (double *)vec, dimension, (double *)(&mat.r), dimension, 0.0, (double *)ret, dimension);とする。横ベクトルになるので、前回やったように、マトリクスのほうを転置してうしろからかけるようにしている。
7.4.4 (D) vDSPのマトリクスとマトリクスのかけ算関数
あとはvDSPのマトリクスとマトリクスのかけ算を使ったmatrix tmat; vDSP_mtransD((double *)(&mat), 1, (double *)(&tmat), 1, dimension, dimension); vDSP_mmulD((double *)vec, 1, (double *)(&tmat), 1, (double *)ret, 1, num, dimension, dimension);とする。考え方はCBLASのマトリクスとマトリクスのかけ算を使ったのと同じだけど、前もって転置したマトリクスを作っておく必要がある。
7.4.5 結果
さて、これでベクトルの個数numを1024から倍々にして8388608(8M個)までそれぞれの時間を測る。他のプロセスで重いものは動かさないようにして実時間で測った。もちろんそれぞれの計算はCPUコアひとつだけを使ってやっている。 結果を図-7に示す。CBLASのマトリクスとベクトルのかけ算(cblas_dgemv)を繰り返したのが遅い(vDSPの2.5倍時間がかかっている)のはまあ当然としても、vDSPと同じやり方でマトリクスとマトリクスのかけ算(cblas_gemm)を使ったのもそれほど速くないのは意外だった。なんだ、CBLASだめじゃん、とここでは思った。
ところが、驚きの結果が。次回に続く....
2013-05-12 21:45
nice!(0)
コメント(0)
トラックバック(0)


コメント 0