ポリゴンレンダラ - その11 [プログラミング]
前回vDSPやCBLASの効率の単純比較をした。比較したのはN×NとN×Mのマトリクスの積のうちNが4という非常に小さな場合だった。今回のポルゴンレンダラにはこれで十分なのでこの結果だけで判断して実装すればいい。でもそれだけでは面白くないのでNがもっと大きい場合も比較してみた。そうするとマトリクスの積なんていう単純な計算なのに思いがけない結果が出た。
やっぱりBLAS/CBLASはすごい。
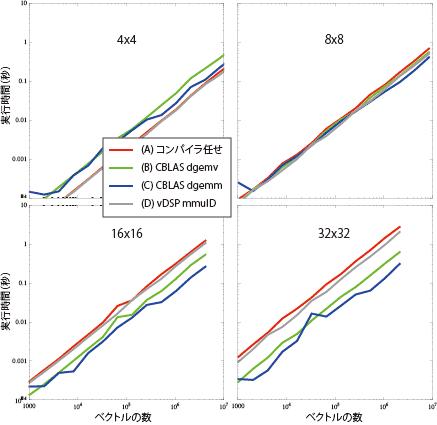 左上は前回の図-7と同じもので、右から下へマトリクスのサイズが4 ×4、8 ×8、16 ×16、32 ×32と大きくなっている。同じベクトルの数でも計算量はサイズの2乗に比例するので、直線がだんだん上にあがっていく。
左上は前回の図-7と同じもので、右から下へマトリクスのサイズが4 ×4、8 ×8、16 ×16、32 ×32と大きくなっている。同じベクトルの数でも計算量はサイズの2乗に比例するので、直線がだんだん上にあがっていく。
おもしろいのは8 ×8で4本の線がほぼ重なって、それ以降はCBLASのふたつがvDSPとコンパイラ任せをおいてけぼりにする。
もっとわかりやすくするために、マトリクスのサイズを横軸にとってプロットしたのが図-9である。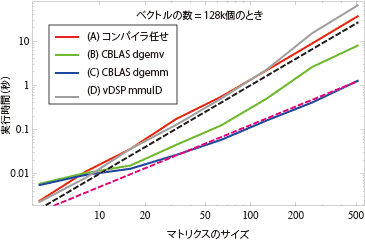 N ×NのマトリクスとNベクトルの積の計算量はN2に比例する。図中の黒点線はN2に比例する線である。コンパイラ任せとvDSPの線は完全に黒点線と平行になっている。ところが特にCBLASのマトリクスとマトリクスのかけ算関数(cblas_gemm)を使った青い線は明らかに寝ている。図中のマゼンタの点線はN√2に比例する直線で、マトリクスのサイズが大きくなるとその直線に漸近している。
N ×NのマトリクスとNベクトルの積の計算量はN2に比例する。図中の黒点線はN2に比例する線である。コンパイラ任せとvDSPの線は完全に黒点線と平行になっている。ところが特にCBLASのマトリクスとマトリクスのかけ算関数(cblas_gemm)を使った青い線は明らかに寝ている。図中のマゼンタの点線はN√2に比例する直線で、マトリクスのサイズが大きくなるとその直線に漸近している。
マトリクスの積は行ごと列ごとに総当たりのかけ算なので、はしょれる項はない。どうやってN√2にできるんだろう?FFTみたいな計算量の減らし方ではない、ということだな。大きな配列ではメモリアクセスも律速要素のはずなのでそこに工夫があるのかな。昔僕がやったみたいなキャッシュにぴったりおさまるような配置なんかを考えてるんだろうか。でもそれだけでN√2まで効率を上げられるんだろうか?
ソースを見ればいいんだろうけど、そこまで元気はないので、先人の英知に敬意を表して次にいこう。
ということで4 ×4のマトリクスで同じことをしたのが図-10である。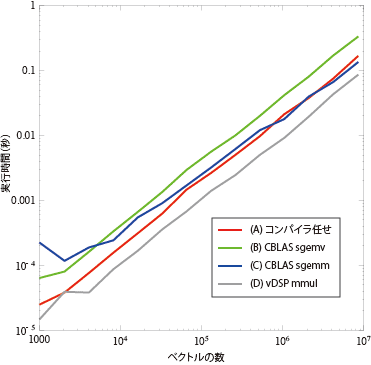 これはvDSPがずっと1番。vDSP以外はdoubleの場合に較べて1割ほどしか速くなってないのに、vDSPはほぼ半分の時間でできている。
これはvDSPがずっと1番。vDSP以外はdoubleの場合に較べて1割ほどしか速くなってないのに、vDSPはほぼ半分の時間でできている。
図-9と同じようにマトリクスのサイズに対してプロットしたのが図-11である。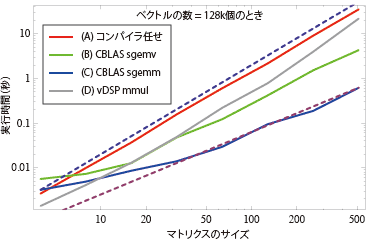 vDSPが優位を保っているのは16 ×16がやっとで、それ以上大きなサイズに対してはCBLASのほうがやはり速くなる。点線は図-9にあるのと同じ意味の線である。CBLASすごいな、やっぱり。
vDSPが優位を保っているのは16 ×16がやっとで、それ以上大きなサイズに対してはCBLASのほうがやはり速くなる。点線は図-9にあるのと同じ意味の線である。CBLASすごいな、やっぱり。
いっぽう、一般のマトリクスとベクトル、マトリクスとマトリクスの積では
それにしてもやっぱりBLAS/CBLASはすごいな。
もうLAPACKの時代ではない、と思っていたんだけどやっぱり40年の歴史は重い。でもできればgslのようなモダンなアイデアに基づいた汎用の数値計算環境が一般的になって欲しい。gslでさえ低レベルのルーチンはBLASを使っている(BLASに依存しないようにもコンパイルできるけど)のでなかなか古いコードから脱却するのは難しいらしい。
gslは計算機数学の専門家が最近の成果を新しい実装に盛り込もうという動機から始まっている。バージョン0台は効率よりもアルゴリズムの正確性に、バージョン1台は基本的な機能の拡充に重きを置いてきた。最近はなんとなくメンテナンスモードに突入か、という感じもしないでもないけど、できればバージョン2はLAPACKを超える計算効率を目指してもらいたい。今の機能を持って効率が上がればLAPACKを置き換えることは夢ではない。
そのためにはまずBLASを置き換える高効率の線形演算パッケージを確立することである。FORTRANのカラムメジャー配列のサポートをやめてその分のオーバーヘッドをなくした新BLASを作って欲しい。
僕もできればコントリビュートしたいけど、gslのメンバにはそうそうたる計算機数学の大家の名前が並んでるのでおこがましい。気持ちの上でコントリビュートすることにする。
やっぱりBLAS/CBLASはすごい。
7.4.6 大きなマトリクスに対する結果
これだけではあまり面白くないのでマトリクスのサイズを大きくしてみた。今回の計算は同次座標の計算なので、4 ×4のマトリクスとベクトルの積ができればいいので、さっきの結果があればいいんだけど、8 ×8、16 ×16とマトリクスを大きくしたらどうなるか、を見てみた。それが図-8。おもしろいのは8 ×8で4本の線がほぼ重なって、それ以降はCBLASのふたつがvDSPとコンパイラ任せをおいてけぼりにする。
もっとわかりやすくするために、マトリクスのサイズを横軸にとってプロットしたのが図-9である。
マトリクスの積は行ごと列ごとに総当たりのかけ算なので、はしょれる項はない。どうやってN√2にできるんだろう?FFTみたいな計算量の減らし方ではない、ということだな。大きな配列ではメモリアクセスも律速要素のはずなのでそこに工夫があるのかな。昔僕がやったみたいなキャッシュにぴったりおさまるような配置なんかを考えてるんだろうか。でもそれだけでN√2まで効率を上げられるんだろうか?
ソースを見ればいいんだろうけど、そこまで元気はないので、先人の英知に敬意を表して次にいこう。
7.4.7 単精度の場合は
これまでの計算は倍精度浮動小数点数(double)について比較したけど、ついでに単精度(float)もやっておこう。ということで4 ×4のマトリクスで同じことをしたのが図-10である。
図-9と同じようにマトリクスのサイズに対してプロットしたのが図-11である。
7.4.8 効率測定のまとめ
以前vDSPのFFTがダントツで速かったので、今回も期待したけどマトリクスの演算ではそれほどではなかった。結局、今回のようなひとつの4 ×4のマトリクスをたくさんのベクトルにかけるとき、- 倍精度ならLLVMコンパイラの最適化はvDSPと、とんとん
- 単精度ならvDSPを使ったほうがいい
いっぽう、一般のマトリクスとベクトル、マトリクスとマトリクスの積では
- 単精度倍精度ともCBLASに優位性がある
- マトリクスサイズが大きいほどより優位で、サイズが512ではvDSPと一桁違う
7.4.9 ということで
今回やりたい同次座標の計算ではvDSPに軍配が上がる。しかし今後は、コンパイラがやる最適化(ベクタユニットへの展開も含めて)がずいぶん進んできてvDSPを使うメリットはだんだん少なくなっていくんだろう。それよりもたくさんあるCPUコアを使い倒すほうに力を注いだほうがいい、ということだな。そうするとますますメモリアクセスが律速するのでそこを最適化する工夫がいることになって、ますます難しくなるな。それにしてもやっぱりBLAS/CBLASはすごいな。
もうLAPACKの時代ではない、と思っていたんだけどやっぱり40年の歴史は重い。でもできればgslのようなモダンなアイデアに基づいた汎用の数値計算環境が一般的になって欲しい。gslでさえ低レベルのルーチンはBLASを使っている(BLASに依存しないようにもコンパイルできるけど)のでなかなか古いコードから脱却するのは難しいらしい。
gslは計算機数学の専門家が最近の成果を新しい実装に盛り込もうという動機から始まっている。バージョン0台は効率よりもアルゴリズムの正確性に、バージョン1台は基本的な機能の拡充に重きを置いてきた。最近はなんとなくメンテナンスモードに突入か、という感じもしないでもないけど、できればバージョン2はLAPACKを超える計算効率を目指してもらいたい。今の機能を持って効率が上がればLAPACKを置き換えることは夢ではない。
そのためにはまずBLASを置き換える高効率の線形演算パッケージを確立することである。FORTRANのカラムメジャー配列のサポートをやめてその分のオーバーヘッドをなくした新BLASを作って欲しい。
僕もできればコントリビュートしたいけど、gslのメンバにはそうそうたる計算機数学の大家の名前が並んでるのでおこがましい。気持ちの上でコントリビュートすることにする。
2013-05-16 21:07
nice!(0)
コメント(6)
トラックバック(0)


Cのrow-major行列の積の計算に、BLAS/LAPACKのdgemmを用いることは、column-majorへの変換(行列転置)を途中に経ることになるのでしょうか?
by zyx (2013-06-05 22:29)
コメントありがとうございます。
ちょっと誤解を招く書き方だったかも知れません。
BLAS/CBLASのレベルではrow-majorとcolumn-majorの違いは、例えばcblas_dgemmではふたつの行列のかけ算順序の違いでしかないので転置はしていません。CBLASはただのグルールーチンでFORTRANのBLASを呼んでいて、転置のスイッチ(CBLAS_TRANSPOSE)に関わらず、計算はcolumn-majorで行われているはずです(僕はソースを当ったわけではないので嘘かも知れませんが)。
しかしLAPACKのレベルでは、行列の行と列にそれぞれ意味があるので、例えばLU分解を(tU)(tL)に分解(tは転置の意味)されても使い道がありません。したがってLAPACKのルーチンを呼ぶときはCのrow-majorの行列を転置してLAPACKに渡す必要があります。
僕が「column-majorのサポートをやめる」というのは、そのことで呼び出しの形式を簡単にできる、という利点が大きいです。例えばcblas_dgemmには引数が13個もあって僕には非常にわかりにくいです。とくに転置とld値(行余白)との関係は悩ましくて、使おうとするたびにいつもCBLASの内部実行エラーが出て苦しみます。
gslにはgsl定義の行列をCBLASで計算するための関数があって、その引数に転置スイッチは残っているのですが、gslのユーザがこの転置スイッチを(column-majorに)使うとは思えません。だとしたらやめればいい、と僕には思えるのですが....
by decafish (2013-06-06 21:53)
どうもありがとうございます。
私の場合では、Cのrow-major行列の積A Bを計算したい場合に、matmul(int m, int n, int l, double *A, double *B) というようなwrapperを書き、その中でBLAS/LAPACKのcolumn-majorなdgemmに積B Aを計算させています。dgemmをそのまま使うのは確かに毎回頭が混乱します。
by zyx (2013-06-06 22:36)
なるほど、やはりそうですか。混乱するのは僕だけではないと知って安心しました。
ラッパを作っておく、というのは賢いやり方ですね。僕は使うたびに同じエラーを出して、引数をいろいろ入れ替えて試すことを繰り返してしまいます。マヌケなやり方です。
やはりシンプルな使い方のできる高性能のライブラリが欲しいです。
by decafish (2013-06-07 07:01)
どうもありがとうございます。
なおC用のLAPACKEを参考に調べると、オプション指定すれば、row-major行列を引数に指定して良いようです。しかしcolumn-majorへの転置が内部で行われオーバーヘッドが発生するとのことで、それでは能がない(失礼)ような気もしました。
by zyx (2013-06-16 00:06)
昔僕がLAPACKを使い始めた頃はCインターフェイスとしてはCLAPACKという、LAPACKを単にf2cで変換してコンパイルしたものしかありませんでした。これなら引数の型に気をつけてFORTRANのルーチンをCから呼んだほうが安心というようなしろものでした。
LAPACKEも単なるグルールーチンだと思ってて使ったことはなかったので、転置スイッチがあるのは知りませんでした。
そういえば、ガチな数値計算屋さんはいまだに「C?なにそれ?」だろうと思ってたのですが、東北大で第一原理計算なんかやってる学生さんたちはCUDAを使い倒すようなコードをCで書いてる、と言っていました。そう言う人たちから新時代の高性能ライブラリが出てこないかなあ、と期待しています。
by decafish (2013-06-16 09:09)