OS XのOpenCL - その17 [OS XのOpenCL]
仕事でお盆休みがなくなりそうな雰囲気を感じつつ、抄訳の続き。今日あたりから佳境に入いってきて、これから徐々に話が濃くなっていく。今日はOpenCLのパフォーマンスをチューニングするときの手順と、アルゴリズムを決めるときの心構えみたいな話。
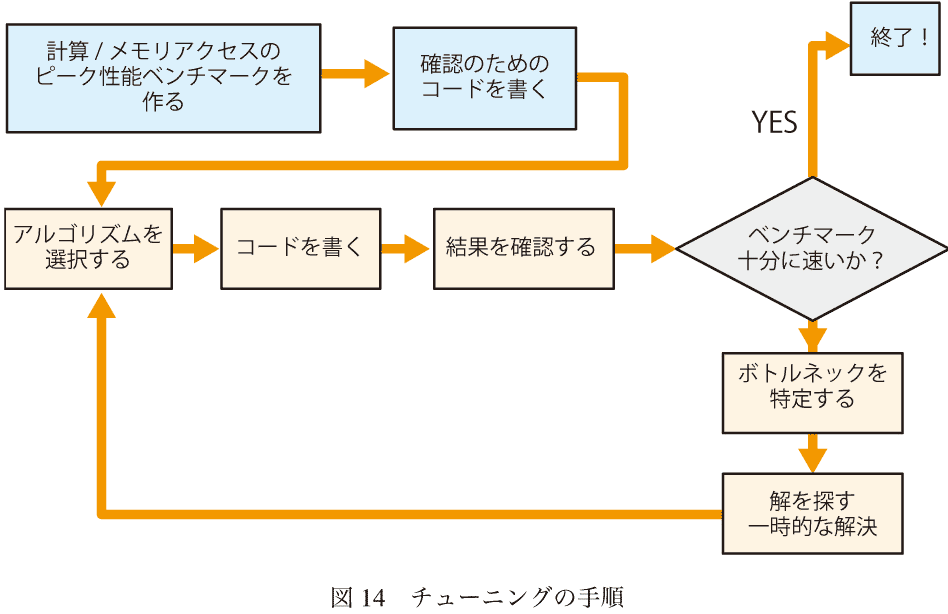
13.5 チューニングの手順
図-14{{decafish : へんなフローチャートだな}}はGPUで効率的に実行できるカーネルの最適化の典型的な手順を示している。- 効率的なアルゴリズムを選ぶ。実行するすべてのデバイスの性能の利点が得られるように最適化されたアルゴリズムなら、OpenCLはたいてい効率的に実行できる。内在的なアルゴリズムを評価することについての提案が「効率的なアルゴリズムを選ぶ」にある
- 目標とするデバイスで効率的に実行するコードを書く。GPUのそれぞれのファミリは固有のアーキテクチャを持っている。GPUの最高のパフォーマンスを得るために、GPUのアーキテクチャを理解する必要がある。例えば、あるGPUファミリはメモリアクセスがあるサイズのときに最もパフォーマンスがよく、ほかのGPUではワークグループがある数の整数倍のときにパフォーマンスがいい、などである。サポートすべきGPUのアーキテクチャの詳細を知るにはメーカの文献を参照のこと。このドキュメントではほとんどのGPUに対して適用できる一般的な方針をだけを提供している。表-を参考に。 普通はまずさいしょにスカラのコードを書くのが良い。つぎにそれを並列化する。さらにメモリの使用量を最小化する
- それぞれのコードが出した結果が正しいかを確認する
- ベンチマーク。ベンチマークコードとアプリのコードの速度を測定するために「デバイスでのパフォーマンスを測定する」に書いた技術が使える。十分なパフォーマンスが得られたならそれで終了である
- ボトルネックを特定する
- 最終解あるいはとりあえずの解決案をみつける
- 最適化の目標を達成するまでこのプロセスを繰り返す
13.6 効率の良いアルゴリズムの選択
OpenCLアプリのアルゴリズムを選ぶときには次のことを考慮すること。13.6.1 アルゴリズムは大規模な並列化をすること
そうすれば計算は独立したたくさんのワークアイテムを使って実行させるようになる。GPUでのデータ並列な計算にとって、たくさんのワークアイテムをデバイスに投入できる場合にOpenCLはうまく動く。13.6.2 メモリの使用量を最小限に抑えること
GPUは巨大な計算パワーを持っている。カーネルはたいていメモリバウンドである。その結果として、メモリアクセスの少ないアルゴリズムか、あるいはメモリに対する計算量の比が高いアルゴリズムがたいていOpenCLアプリにとってよろしい。メモリに対する計算量の比とは浮動小数点演算回数とメモリとの読み書きによる転送バイト数の比である。 複数の出力エレメントの計算をひとつのワークアイテムにグループ化することで、独立な依存チェインの数を最大化するように試すこと。13.6.3 OpenCLデバイスとのデータのやり取りは高価である
OpenCLは大きなデータセットに対して最も効率が良い。OpenCLではメモリアロケーションとホスト-デバイス間のメモリ転送の制御が完全に可能である。書いて計算して読み込むことを繰り返すより、OpenCLデバイスでメモリを確保してデータをデバイスに転送して、できる限りデバイスで計算して、そのあと書き戻すようなアプリはより速くなる。 遅いホスト-デバイス間の転送を避けるためには- 可能な限り複数の転送をひとつの大きな転送にまとめること
- 可能な限りデータをデバイスに置いておくようにアルゴリズムを設計すること
13.6.4 データ並列の計算をGPUでやるとき、OpenCLはデバイスにたくさんのワークアイテムが投入されるのが一番うまく動く
しかしアルゴリズムの方が影響が大きい13.6.5 可能ならかならずOpenCLのビルトイン関数を使うこと
それらの関数では最適化されたコードが生成される。13.6.6 精度とスピードのバランスをとること
GPUはグラフィクス用に設計されていて、それはあまり精度は必要ない。最速の別物がOpenCLビルトインのfast_、half_、native_ 関数にある。スピード制御のためのビルドオプションがいくつか提供されている13.6.7 OpenCLのリソース(メモリオブジェクト、カーネルなど)の確保と解放には時間がかかる
それらを解放して新しく確保する代わりに再利用すること。しかし、イメージオブジェクトは同じサイズとピクセルフォーマットの場合だけにしか再利用できないことに注意13.6.8 デバイスのメモリサブシステムを活用すること
OpenCLデバイスでメモリを使うとき、ひとつのワークグループのすべてのワークアイテムで共有されるローカルメモリのほうが、デバイスのすべてのワークグループで共有されるグローバルメモリよりも速い。ひとつのワークアイテムだけで使えるプライベートメモリはさらに速い。 GPUではメモリアクセスのパターンが最も重要な要素である。最適化しきれていないパターンの代わりにしたり、遅いグローバルメモリへのアクセスを最小限にするために、速いレベルにあるメモリ(ローカルメモリ、レジスタ)を使うこと。13.6.9 もっともうまく動くカーネルサイズを探すために実験すること
小さなカーネルを使うと効率的になる場合がある。なぜなら小さなカーネルは少ししかリソースを使わないからである。ジョブを小さなカーネルに細分化すると大きくて効率的なワークグループを作れるようになることがある。一方でそれぞれのカーネルを開始するのに10から100μ秒かかる。グローバルメモリの読み書きは高価なので、たくさんのカーネルをひとつの大きなカーネルに集約することはオーバーヘッドを減らすこともある。 最適なパフォーマンスが得られるカーネルサイズを見つけるには実験が必要である13.6.10 GPUでのOpenCLイベントは高価である
キューの実行を調整するのにイベントを使うことができるが、そのためのオーバーヘッドが存在する。どうしても必要なときだけにイベントを使うこと。でなければキューの整列プロパティを利用すること13.6.11 分岐を避けること
GPUでスケジュールされたすべてのスレッドは同じコードを実行する。つまり、条件式を実行するときはすべてのスレッドが分岐の両方を実行して、条件が成り立たないほうの分岐が出力しないようにしている。条件式を使わないか(a?x:y演算子に置き換える)か、ビルトイン関数を使うのが一番いい。2015-08-05 21:40
nice!(0)
コメント(1)
トラックバック(0)


沒有醫生的處方
acheter cialis meilleur pri http://kawanboni.com/ Cialis generico
by Cialis great britain (2018-04-14 17:29)