OS XのOpenCL - その19 [OS XのOpenCL]
会社は休みなのに出てる。ところが今日になって設計前提をひっくり返すちょんぼが見つかった。これ以上出ても意味がないので明日善後処理して、残りは休むことにする。結局休みの少なめの人のお盆休みと同じになる。ところで、ダリ風の格言
「光には2種類ある。s-偏光とp-偏光だ」
で、今日発覚した失策を心に刻むことにする。
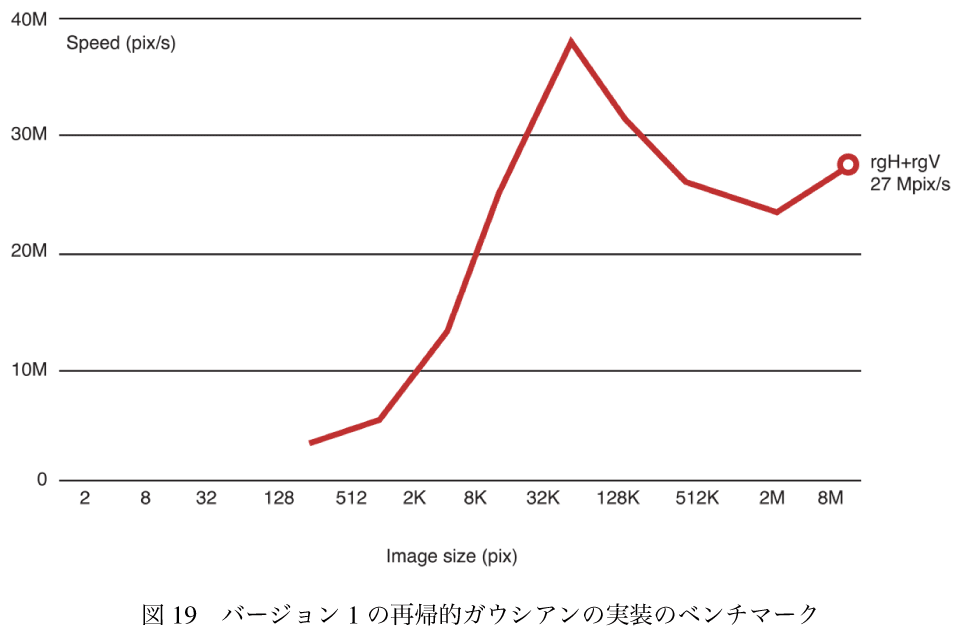
ということで、前回効率がいいと結論付けたアルゴリズムをナイーブに実装して、その効率を測定する。これを出発点にして効率を上げていく話。
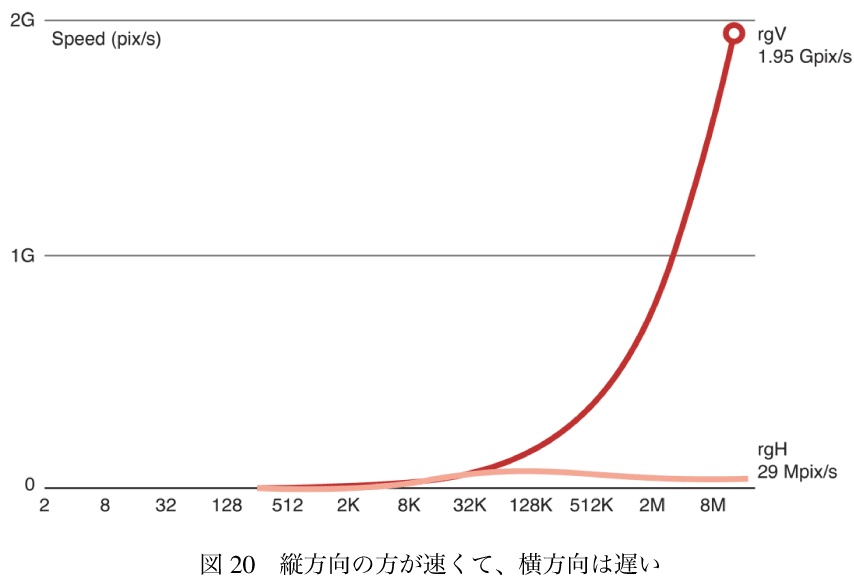
 縦方向の方が速くて、横方向は遅い。
縦方向の方が速くて、横方向は遅い。
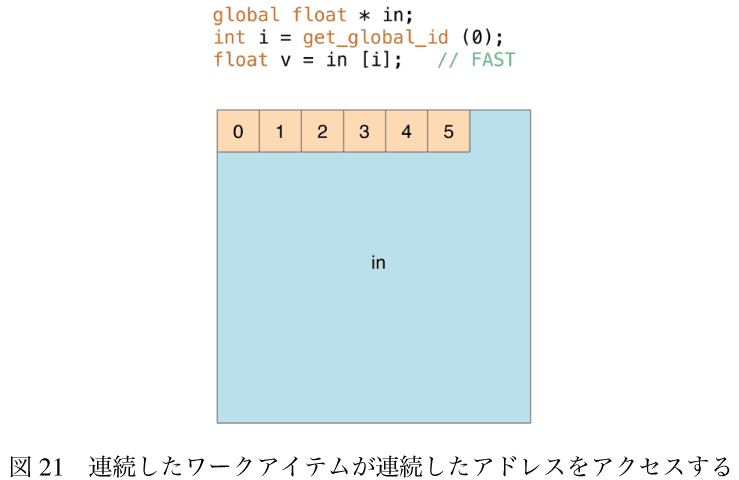
 問題はGPUの中で同時におよそ300ワークアイテムのグループからおよそ1600万回関数が呼ばれるようにスケジュールされていて、同じタイミングで異なるアドレスのメモリが要求されている。これはメモリアクセスパターンの例である。GPUは特定の種類のメモリアクセスに対して最適化されていて、それ以外の種類のアクセスでは競合が起こる。これは直列に実行されることになって遅くなる。とりわけ、図-21に示すように画像の処理では同じ行の連続するワークアイテムは連続するピクセルをアクセスするとき、処理は速くなる。
問題はGPUの中で同時におよそ300ワークアイテムのグループからおよそ1600万回関数が呼ばれるようにスケジュールされていて、同じタイミングで異なるアドレスのメモリが要求されている。これはメモリアクセスパターンの例である。GPUは特定の種類のメモリアクセスに対して最適化されていて、それ以外の種類のアクセスでは競合が起こる。これは直列に実行されることになって遅くなる。とりわけ、図-21に示すように画像の処理では同じ行の連続するワークアイテムは連続するピクセルをアクセスするとき、処理は速くなる。
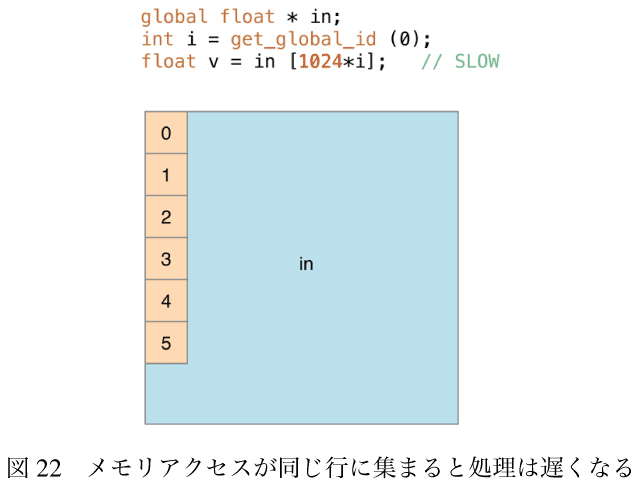
 しかし、図-22にあるようにメモリアクセスが最終的に同じ行をアクセスするような場合(画像の処理は連続するワークアイテムが同じ列の連続するピクセルをアクセスしている)、処理は遅くなる。
しかし、図-22にあるようにメモリアクセスが最終的に同じ行をアクセスするような場合(画像の処理は連続するワークアイテムが同じ列の連続するピクセルをアクセスしている)、処理は遅くなる。
 それに対する解決は横方向が縦になるように行列を転置することである。
画像を転置して、そのあともとの方向に転置し直す。
それに対する解決は横方向が縦になるように行列を転置することである。
画像を転置して、そのあともとの方向に転置し直す。
(1)
転置するには、転置となるようにピクセルをコピーすればいい。
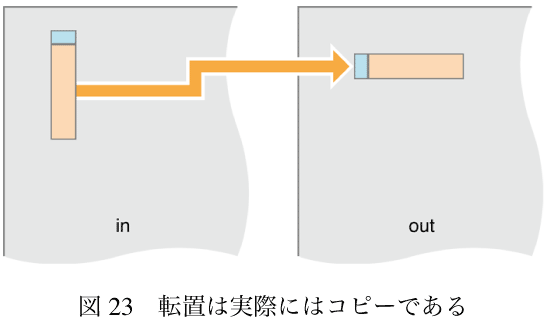 転置はコピーカーネルとほとんど同じくらい速い。しかし入力バッファのアクセスは速いのに出力バッファのアクセスは遅くなる。
転置はコピーカーネルとほとんど同じくらい速い。しかし入力バッファのアクセスは速いのに出力バッファのアクセスは遅くなる。
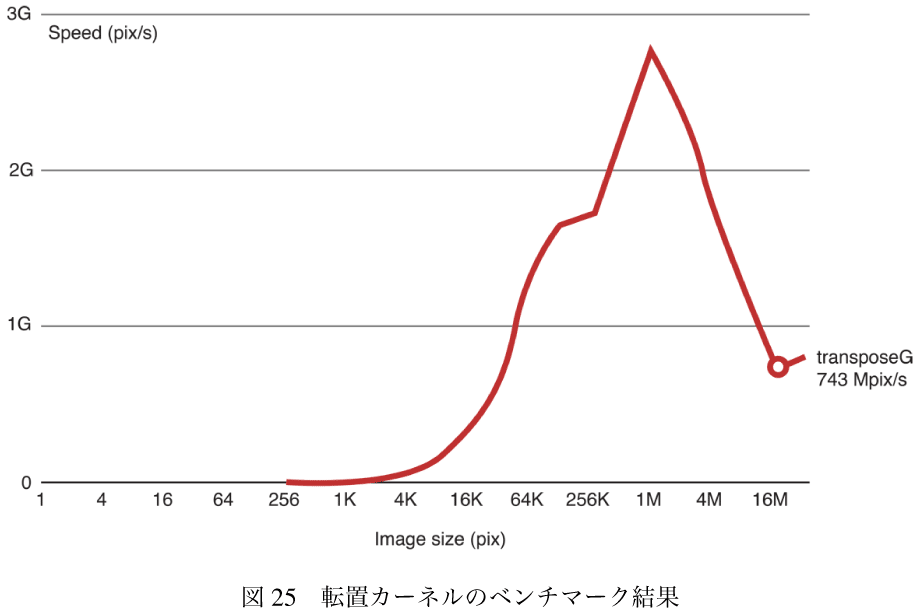
 それぞれのパスで転置のための2回のI/O処理を加えることで転置カーネルのパフォーマンスを見積もると、10+2*2=14となる。
それぞれのパスで転置のための2回のI/O処理を加えることで転置カーネルのパフォーマンスを見積もると、10+2*2=14となる。
Table 2: 転置カーネルの見積結果
このコードを実行すると、画像の縦が大きくなると処理は遅くなる。
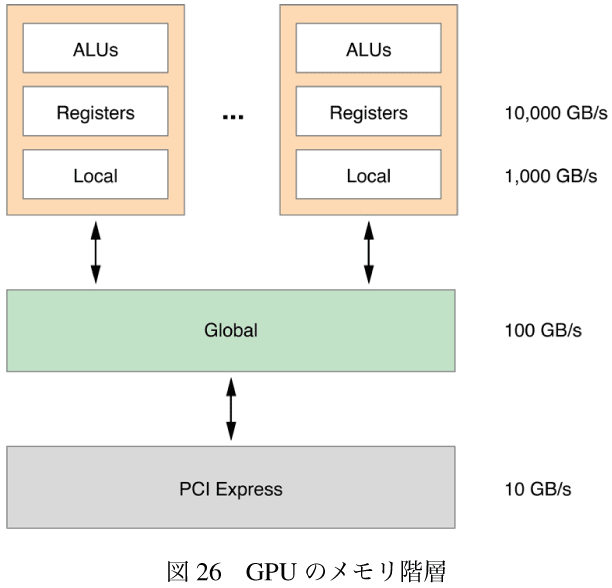
 これを加速するには、処理をより速いメモリに移動させればいい。GPUの内部では処理コア(図-26の一番上の箱)がある。それぞれの処理コアは演算装置(ALU)とローカルなメモリを持っている。処理コアはグローバルメモリに接続されている。グローバルメモリはホストに接続されている。それぞれのメモリの層はその下よりも10倍速い。
これを加速するには、処理をより速いメモリに移動させればいい。GPUの内部では処理コア(図-26の一番上の箱)がある。それぞれの処理コアは演算装置(ALU)とローカルなメモリを持っている。処理コアはグローバルメモリに接続されている。グローバルメモリはホストに接続されている。それぞれのメモリの層はその下よりも10倍速い。
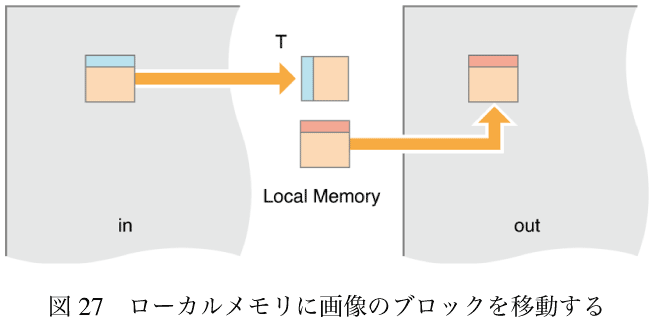
 この繰り返し計算では、処理をローカルメモリに移動させる。ワークグループ(ワークアイテムのかたまり)を使って、画像の小さいかたまりを読み込んでローカルメモリに保存する。そのあとグループ内のすべてのワークアイテムがローカルメモリ内の画素のガウシアン再帰処理を終わらせたら、それを出力バッファに書き出す。
この繰り返し計算では、処理をローカルメモリに移動させる。ワークグループ(ワークアイテムのかたまり)を使って、画像の小さいかたまりを読み込んでローカルメモリに保存する。そのあとグループ内のすべてのワークアイテムがローカルメモリ内の画素のガウシアン再帰処理を終わらせたら、それを出力バッファに書き出す。
 コードは次のようなものである。
コードは次のようなものである。
「光には2種類ある。s-偏光とp-偏光だ」
で、今日発覚した失策を心に刻むことにする。
ということで、前回効率がいいと結論付けたアルゴリズムをナイーブに実装して、その効率を測定する。これを出発点にして効率を上げていく話。
13.7.4 最初のバージョン
再帰的ガウシアンアルゴリズムを使った最初のバージョンのガウシアンブラーのコードはつぎののようなものである。
// これは横方向のパスである
// ひとつの出力行に対してひとつのワークアイテムが
// 画像のそれぞれの行(yで指定される)に対して実行される
kernel void rgH(global const float * in,global float * out,int w,int h)
{
int y = get_global_id(0); // 処理する行
// 前方パス
float i1,i2,i3,o1,o2,o3,o4;
i1 = i2 = i3 = o1 = o2 = o3 = o4 = 0.0f;
// ループのそれぞれの繰り返しの中で
// ひとつの入力値を読んでひとつの出力値を書き出す
for (int x=0;x<w;x++)
{
float i0 = in[x+y*w]; // Load
float o0 = a0*i0 + a1*i1 + a2*i2 + a3*i3
- c1*o1 - c2*o2 - c3*o3 - c4*o4; // 新しい出力を計算
out[x+y*w] = o0; // Store
// 次のピクセルのために値をローテート
i3 = i2; i2 = i1; i1 = i0;
o4 = o3; o3 = o2; o2 = o1; o1 = o0;
}
// 後方パス
...
}
// これは縦方向のパスである
// ひとつの出力行に対してひとつのワークアイテムが
// 画像のそれぞれの行(xで指定される)に対して実行される
kernel void rgV(global const float * in,global float * out,int w,int h)
{
int x = get_global_id(0); // 処理する列
// 前方パス
float i1,i2,i3,o1,o2,o3,o4;
i1 = i2 = i3 = o1 = o2 = o3 = o4 = 0.0f;
for (int y=0;y<h;y++)
{
float i0 = in[x+y*w]; // 読み込み
float o0 = a0*i0 + a1*i1 + a2*i2 + a3*i3
- c1*o1 - c2*o2 - c3*o3 - c4*o4;
out[x+y*w] = o0; // 書き出し
// ローテート
i3 = i2; i2 = i1; i1 = i0;
o4 = o3; o3 = o2; o2 = o1; o1 = o0;
}
// 後方パス
...
}
この繰り返しプロセスは図-19のような結果になる。
| rgV + transpose + rgV + transpose = rgV + rgH |
| アルゴリズム | メモリ | 計算 | 計算/メモリ | 見積 |
| (浮動小数点R+W) | (flops) | 比率 | (MP/秒) | |
| V+T+V+T | 14 | 64 | 4.6 | 2,030 |
kernel void transposeL(global const float * in,
global float * out,
int w,int h)
{
local float aux[256]; // ブロックサイズは16x16
// bxとbyはワークグループの座標である
// 画像のbxとbyのブロックにマップされる
int bx = get_group_id(0), // (bx,by) = 入力ブロック
by = get_group_id(1);
/// ixとiyはブロック内での画素の座標である
int ix = get_local_id(0), // (ix,iy) = ブロック内の画素
iy = get_local_id(1);
in += (bx*16)+(by*16)*w; // 入出力ブロックの原点に移動
out += (by*16)+(bx*16)*h;
// それぞれのワークアイテムはテンポラルなローカルメモリに一つの値を読み込む
aux[iy+ix*16] = in[ix+w*iy]; // ブロックを読む
// すべてのワークアイテムを待つ
// このバリアはワークグループ内のすべてのワークアイテムが aux[…] = in[…]を実行し終って
// auxの値すべてが正しいことを確実にするためである
// そのあとであればout[…] = aux[…]が実行できる
// これはそれぞれのワークアイテムがauxの一つの値を設定して他のワークアイテムが設定したものを
// 読み込むために必要となる
// ここで同期を取らないと、設定されてない値を読んでしまうことがあり得る
barrier(CLK_LOCAL_MEM_FENCE); // 同期
// 連続したメモリのコピーなので、書き出しは速い
// ローカルメモリからグローバルメモリに値を書き出す
out[ix+h*iy] = aux[ix+iy*16]; // ブロックの書き出し
}
2015-08-11 21:11
nice!(0)
コメント(4)
トラックバック(0)


以前 OpenCL でキャプチャカードから取り出した映像を NSView で描画する方法を試行錯誤してた際に参考にさせていただきました。最近は OpenGL/OpenCL + NSOpenGLView/CAOpenGLLayer よりも Metal+MTKView の方が書きやすいですね。
macOS の API は pthread や OpenGL/OpenCL といった標準規格のものがきちんとありますが、最近は dispatch や Metal に比べると古い実装のままで残念なことが多いです。
sem_timedwait がなくて OSS のビルドで頭を抱えたり、OpenCL 1.2 の実装が甘かったり、新しい API を使えと強要する仕様になっていますね。最適化のしやすさが違うので仕方ない部分もあるとは思いますけど書く方は大変でした。
素朴な疑問なのですが、ベクトル型や組み込み函数を使われていないのは何か理由があるのでしょうか。SIMD はベクトル処理で真価を発揮すると思います。SSE などでもそうですが、可能な限り演算の回数を減らすように書いた方が良いのではないでしょうか。例えば最初の rgH は
float4 i = 0, o = 0, iv, ov;
for (int x = 0; x * 4 < w; x++)
{
iv = in[x+y*w]; // iv = *in++;
i.x = iv.x;
ov.x = dot(a, i) - dot(c, o);
i.s1234 = i.s4123; o.s1234 = o.s4123;
o.x = ov.x;
i.x = iv.y;
ov.y = dot(a, i) - dot(c, o);
i.s1234 = i.s4123; o.s1234 = o.s4123;
o.x = ov.y;
i.x = iv.z;
ov.z = dot(a, i) - dot(c, o);
i.s1234 = i.s4123; o.s1234 = o.s4123;
o.x = ov.z;
i.x = iv.w;
ov.w = dot(a, i) - dot(c, o);
i.s1234 = i.s4123; o.s1234 = o.s4123;
o.x = ov.w;
out[x+y*w] = ov; // *out++ = ov;
}
のようにかけると思います。in, out は float4 の配列に読み替え、dot は内積、値を flip できるそうですが未確認、ベクトルにスカラーやベクトルを代入する Fortran 的な記法も使えたと思います。計算回数が減っているので最大で四倍速といったとこでしょうか。float16 などより大きいベクトルを使えば global へのアクセスが減るのでより早くなるかもしれません。
後はテクスチャやら計算用バッファを適宜使うとメモリ効率がよくなったような気がします。clCreateBuffer, clCreateFromGLTexture とかだったと思います。ここら辺は Metal の方がやりやすかったように思います。
by お名前(必須) (2020-11-27 19:43)
コメントありがとうございます。
僕はOpenCLに挫けてしまった人間なので何もいえません。効率よくOpenCLが書けるというのは僕から見るとすごいことに思えます。
Appleはオープンな仕様を捨ててAppleプロプライエタリなもので固めようとしているようです。OpenGL、OpenCLはObsoleteでMetalを使え、ですし、pthreadなんかも中身はGCDで書き換えられているみたいです。
先日のM1もハードで同じことをしよう、ということだと思います。
僕が若い頃の電気業界の垂直統合戦略を思い出します。
なお、ベクトル型が使われていないのはよくわからないです。このあたりのコードは僕のではなくて、Appleのドキュメントからのものです。ただ、gccの時代でもコンパイラが解析して自動的にベクトル化されることがありました。LLVMはソース解析が強力なのでベクトル化はコンパイラ任せる、ということなのかもしれません。ARM64では浮動小数点演算は単項でもベクタユニットの仕事ですし、アセンブラレベルでも統合されているみたいですし。
OpenGLよりMetalの方が簡単という話は他所でもよく伺うのですが、僕にはまだ難しいです。簡単なことをするにも結構手順が長くて、読み進めるうちに最初の方を忘れてしまいます....
by decafish (2020-11-28 10:05)
ドキュメントのコードだったんですね。関連記事? に OpenCL でも効率があまり上がらなかったと書かれていたように思うのですが、どのようなコードか気になって、ベクトル化されてないのは何故なのだろうと考えた次第です。
icc 使うとベクトル化されるよみたいな話は聞いたことありましたが gcc もやってたんですね。LLVM でもベクトル化されてたんでしょうか。最近のプログラムは並列処理を組み込むので単純なベクトル化とは相性が悪い気がします。OpenMP のドキュメントには SIMD 化を明示できるとか書いてありましたが、やったことないのでちょっとわかりません。
アセンブラ吐かせても何がおきてるかわからないので、何パターンか書いてベンチマークをとり、結果だけ信じるようにしています。
プログラマが機械を意識しなくていい時代はまだ当分来そうにありませんが、macOS では Metal が大変オススメです。仕様通り動いてくれるので、なぜ動かないのか悩む時間が減って少し生産的になります。iOS のおかげかサンプルコードがすぐ見つかる点もやりやすかったですね。
by お名前(必須) (2020-11-28 14:30)
実は、このあたりのコードを真似して自分で、GigEカメラのベイヤ配列データからRGBに変換するのとか、モノクロデータをRainbow表示する(よくある光強度の強いところは赤で弱いところは青で、というの)とかをOpenCLで書きました。ところが全然速くないどころか、CPUでやるのよりかえって遅くて、OpenCLとは難しいもんだ、とつくづく思って諦めました。かなり時間をつぎ込んだので諦めるのは悔しかったのですが、あのとき明示的にベクトルを書くとマシになっていたのでしょうか。サンプルコードによってはSIMDデータ型を使っているのもあったので、やってみればよかったかもしれません。
LLVMは少なくともx64にはデフォルトで勝手にベクトル化するようです。もう随分前ですが、浮動小数点演算が続くとベクトルのコードを吐くのをアセンブラで確認したことがあります。元のコードの何かをちょっといじるとスカラのコードになったりしたので、これも結構微妙だなとそのときは思いました。
今ではSwiftからもSIMDを明示的に呼べるようになっているので、ガチガチに組みたいときはそのほうがいいようですが、中途半端にやるとコンパイラのコードに負けたりしてまた悔しい思いをすることになります。Swiftだとなるべくimmutableなstructの集合として書くような癖がついて、それだとスレッドセーフにしやすいので大きなSIMDのコードも書きやすくなりました。
その昔、OpenCLを勉強していた頃や、もっと前のObjective-Cと格闘しはじめた頃は、サンプルやドキュメントが限られていていましたが、今ではSwiftならすぐ見つかります。これはありがたいです。色々なレベルの日本語解説も豊富になりましたし。昔の苦労が嘘のようです。
by decafish (2020-11-28 18:39)