ヘッドレスでのX11サーバ その2 [Raspberry Pi]
こないだから、ある問題のためにRaspberry PiでのMathematicaを使い倒すことを考えている。先日の問題はそうやってどうにか解決したんだけど、Raspberry Piの場合X11サーバをRaspberry Pi側に置くのがいいのか、と悩んでしまう。以前、X11サーバをmacOS側で動かして、レスポンスがVNCよりかえって遅い、という現象に出会ってVNCを使うしかないのか、と思っていた。しかしそれはいろいろな要素が絡んでいて一概には言えない。
ここでもう一度整理して、Rasbperry Pi OSでMathematicaを動かす場合に、どういう方法が一番いいのか試してみようと思う....
本来のRaspberry Piの使い方の想定というのは、こういうものだった。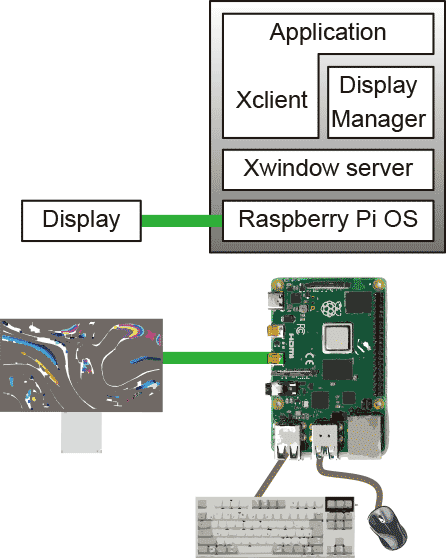 つまり、スタンドアロンで、ディスプレイはうちのテレビを、キーボードとマウスはお父さんのを借りてね、と子供たちに最小限の出費で自分のコンピュータを持ってもらおう、というのが主旨だった(高い志とそれを実現する能力とを併せ持ったプロジェクトで、僕は素晴らしいと思う。僕に欠けた要素なのでよけいそう思うんだけど)。
つまり、スタンドアロンで、ディスプレイはうちのテレビを、キーボードとマウスはお父さんのを借りてね、と子供たちに最小限の出費で自分のコンピュータを持ってもらおう、というのが主旨だった(高い志とそれを実現する能力とを併せ持ったプロジェクトで、僕は素晴らしいと思う。僕に欠けた要素なのでよけいそう思うんだけど)。
こういうスタンドアロンな使い方をしている人はたぶん大勢いるだろう。特にRaspberry Pi以外にコンピュータを持っていない子供たちはこうする以外に方法がない。そしてこれで十分動くようにRaspberry Piは設計されているので、普通のパソコンに比べればちょっと遅い、という以外は全く問題がない。
ところが、子供たちだけではなく、僕みたいにRaspberry Piを安価なlinuxマシンとして使おうという大人が現れて、群がるようになってきた。そういう大人たちはすでにパソコンを持っていて、Raspberry Pi専用にディスプレイやキーボードやマウスを用意するというのは邪魔なだけでパソコンから使えるようにしようと考えた。
最初はリモートログインで、パソコンのターミナルからRaspberry Pi側のShellを起動していたけど、大人たちはmacOSやWindowsのGUIに慣れてしまっていて、Shellだけでは煩わしく感じた。そこで次にやるのがVNCである。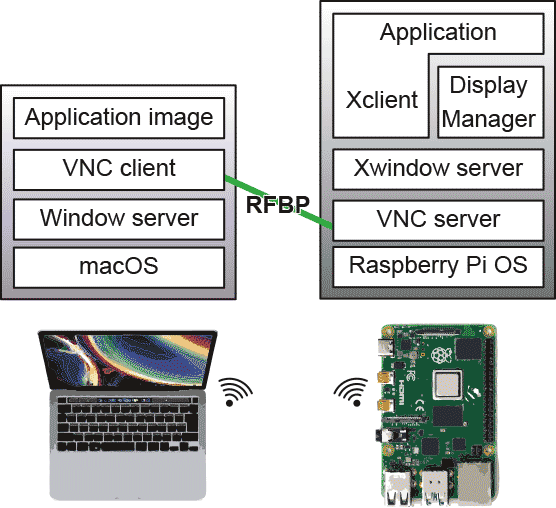 これはスタンドアロンと実質的にはかわりなくて、VNCというソフトウェアによって、単にディスプレイキーボードマウスなんかを直接繋ぐ代わりに、LAN経由でパソコン付属のそれらを使えるようにする、というもの。これは普通のパソコン同士でも使うことがあって大人たちは慣れていた。
これはスタンドアロンと実質的にはかわりなくて、VNCというソフトウェアによって、単にディスプレイキーボードマウスなんかを直接繋ぐ代わりに、LAN経由でパソコン付属のそれらを使えるようにする、というもの。これは普通のパソコン同士でも使うことがあって大人たちは慣れていた。
しかしVNCはディスプレイ画面を画像情報としてパソコンに常時流す必要がある(もちろん全画素を送るのではなくいろいろな圧縮をした上でやりとりしている。上の絵のRFBPはRemote Frame Buffer Protocolでそのとりきめに従っている。ちなみにXウィンドウのクライアントサーバの位置づけとVNCのそれとでは逆になっているような感じがする。ややこしい)。パソコンにとってネットワークトラフィックや表示に関するオーバーヘッドは大したことはないけど、Raspberry Piにはそこそこ重い。Raspberry PiでLチカやエディタを動かすぐらいなら問題なはいけど、Raspberry Piのコアを使い倒そうとするとVNCは邪魔な存在と言える。
Raspberry Piの標準OSであるRaspberry Pi OS(長いな。旧Raspbian)はGUIにX11ウィンドウシステムを使っている。さっきから絵に描いているように、X11サーバがディスレイへの表示、キーボードやマウスからの入力(Xイベントという)処理を一括してやっている。入出力の必要なアプリケーションはXクライアントとして、X11サーバに依頼する、という形をとる。このやりとりのしかたはXプロトコルといって非常にシンプルな手順に従っている。
X11サーバをパソコン側で動かす、ということも可能である。こうすればVNCは使わずに済む。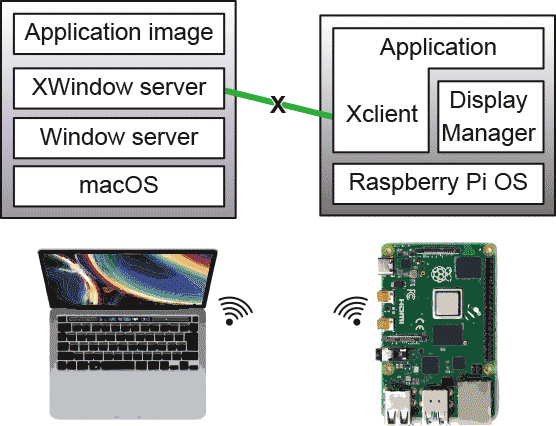 もともとXプロトコルはネットワーク上のどこでも使えるようにかならずネットワークを(ローカルな場合はlocalhost、127.0.0.1を)経由するように作られている。従って、Raspberry Pi側ではXクライアントだけを動作させて、Xプロトコルはネットワークに流せばいい。その昔Xウィンドウシステムが作られた当時からこういう使われ方をしていて、Xサーバを動かすだけ(つまり表示と入力のデバイスだけを持つ)でファイルシステムを持たないマシンも作られていた。ようするに、VNCを使うとネットワーク機能がダブっていた、ということになる。
もともとXプロトコルはネットワーク上のどこでも使えるようにかならずネットワークを(ローカルな場合はlocalhost、127.0.0.1を)経由するように作られている。従って、Raspberry Pi側ではXクライアントだけを動作させて、Xプロトコルはネットワークに流せばいい。その昔Xウィンドウシステムが作られた当時からこういう使われ方をしていて、Xサーバを動かすだけ(つまり表示と入力のデバイスだけを持つ)でファイルシステムを持たないマシンも作られていた。ようするに、VNCを使うとネットワーク機能がダブっていた、ということになる。
またXウィンドウシステムでは、ディスプレイマネジャもネットワーク上のどこにあってもいい、ということになっている。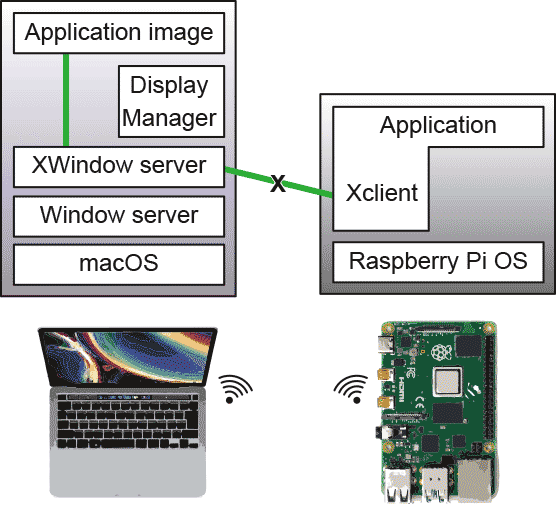 ディスプレイマネジャというのは、表示の外観を決めたり、フォント展開の指示をしたり、メニューを出してユーザの指示に反応したり、ウィンドウを動かしたり大きさを変えたり、プロセスの調停(Xサーバはディスプレイにひとつだけど、XクライアントはたくさんあっていろんなプロセスからXサーバに要求を出す)をユーザにわかりやすくしたり、という雑用を担っている。
ディスプレイマネジャというのは、表示の外観を決めたり、フォント展開の指示をしたり、メニューを出してユーザの指示に反応したり、ウィンドウを動かしたり大きさを変えたり、プロセスの調停(Xサーバはディスプレイにひとつだけど、XクライアントはたくさんあっていろんなプロセスからXサーバに要求を出す)をユーザにわかりやすくしたり、という雑用を担っている。
今の多くのパソコンOSではウィンドウサーバとディスプレイマネジャは一体化しているけど、Xプロトコルの場合はディスプレイマネジャとの通信もXプロトコルを使うので、こういうことが可能になる。ここまでくると、Raspberry Pi側はshellを起動してコマンドラインで使うのと、少なくともプロセス数だけで比べれば大して変わらなくなって、Raspberry Pi側の仕事は楽になるはずである。
いや、楽になるはずだった。ところがあんがいそうではない。何がボトルネックかというと、Xプロトコルは設計が古き良き時代の、セキュリティの心配なんて誰も考えもしなかった頃に作られたものだった。せいぜいxhostで接続可能なホストを制限したり、xauthで権限を設定したり、という程度で、ネットワークには裸のXプロトコルが流れていた。
その後、セキュリティの厳しい時代になって、それはないだろ、ということに当然なった。Xプロトコルを暗号化しようという話が始まった。ところがもともとそんなことを考えないで作られたので、始めてみると思わないところに穴があいたり、それを塞いでいるうちにセキュリティの概念が厳しくなったりして、どんどん後追い後追いになっていった。複雑で効率が悪い、どっかのスラム街のようになっていった。
そして、スッパリ諦めた。こだわりなく諦めるというのは、実はすごく偉い。どこぞの誰とかとはそもそも大きく違うところである。Xプロトコルを堅牢にするのではなく、sshをトンネルに使おう、というわけである。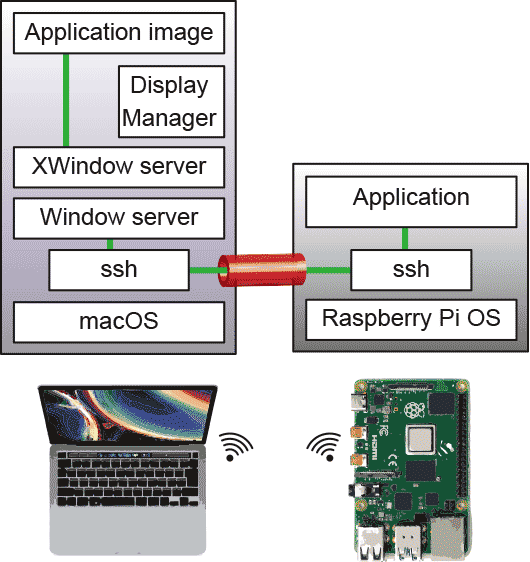 sshはネットワーク間の通信を安全に行うためのプロトコルとその実装で、今得られる認証方法や暗号に関する最新の技術が盛り込まれた上に、使い勝手の良さや通信効率も考慮されたもので、セキュリティの保全はすべてsshにまかせて、Xプロトコルはsshトンネルの出入り口では簡単で軽い、昔のままのものを使うことにした。
sshはネットワーク間の通信を安全に行うためのプロトコルとその実装で、今得られる認証方法や暗号に関する最新の技術が盛り込まれた上に、使い勝手の良さや通信効率も考慮されたもので、セキュリティの保全はすべてsshにまかせて、Xプロトコルはsshトンネルの出入り口では簡単で軽い、昔のままのものを使うことにした。
そのおかげで、認証やその設定が非常に複雑になっていたのが、sshの設定さえできていればそれでよくなった。暗号化したXプロトコルは非常に重くなったが、sshの通信効率がいいためにトンネルしてもかえって反応がいい、ということになった。すばらしい。
macOSの場合、ターミナルを開いて
また、このためには/etc/ssh/sshd_configの中に
これでリモートログインして、Xプロトコルを使うコマンドを実行すると、macOS側で、XQuartz(X11のmacOSの専用実装。ディスプレイマネジャは原則としてはmacOSのウィンドウマネジャに付随したAqua(quartz-wmというコマンドで、実際の調停はOS本体のウィンドウマネジャに依頼する)が使われる。Aquaがデザインの名前なのか、ウィンドウマネジャまで包含するのか、よくわからない)が自動的に起動して、macOSのlook-and-feelになるべく近くなるような形で動作するようになっている。
面白いのは、Rspberry Pi側でのDISPLAY変数が
ちなみに、Xquartzは最終リリースがもう4年前で、コードで言えば実質的に7年ほど前のがそのまま使われている。放置プレイと言っていい。まあ、X11そのものも充分枯れていてsshをトンネルすると決断したあと、基本的な考え方に変化はない。売り物のソフトウエアではユーザから金を巻き上げるために盛んにバージョンアップする必要があるけど、40年近い歴史のあるXでは、完成された部分に手を入れる必要はない。
ということで、Mathemtica以外のプロセスをなるべく減らして、Mathematicaだけをぶん回したらどうなるか、というのを試してみた。まずそれぞれでコア数に比例したMathemetica Kernelを起動する。 などと表示される。Raspberry PiのほうはX11サーバも起動せず、小さなデーモンを除くと実質的にMathematicaだけが動いている状態にした。
などと表示される。Raspberry PiのほうはX11サーバも起動せず、小さなデーモンを除くと実質的にMathematicaだけが動いている状態にした。
このあと4つの計算をさせて実行時間を比較した。どれもKernelを使い倒すものにした。まずひとつめは
ふたつめもドキュメントにある
みっつめは
よっつめは
この4つをiMac、MacBook Pro、Raspberry Pi 4B、Raspberry Pi 3Bで比較した。この4つだけなら、Xウィンドウは必要なく、リモートシェルだけでいいんだけど、そこは僕の本来の目的に沿うようなベンチにするため。それはそれとして、結果がこれ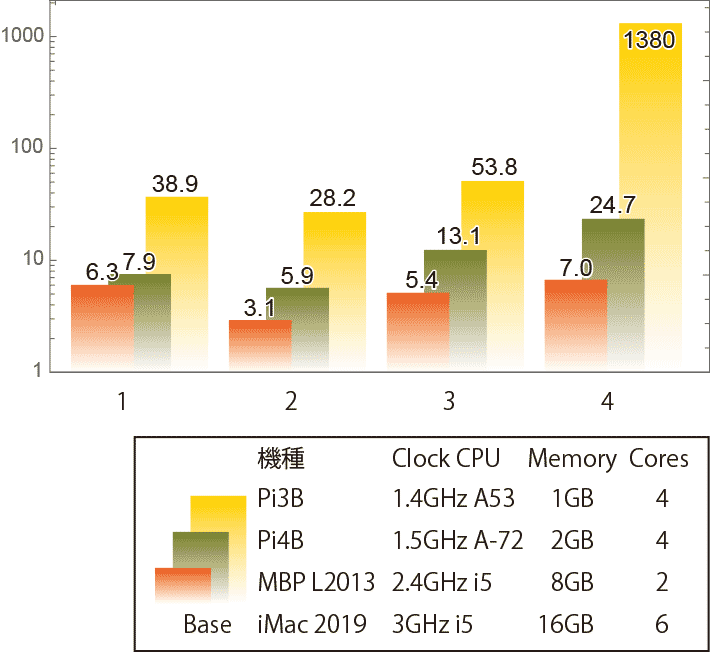 それぞれの実行時間をiMacの結果を1としてログプロットした。面白いのはMBPとPi4とではだいたい倍ぐらい遅いだけ、という結果。MBPのコア数は2個なのでそのせいもあって近づいていると考えられるが、前回のシングルカーネルの結果に比べるとかなり差が圧縮されている。とくにほぼ倍精度浮動小数点演算だけのひとつめのベンチではほとんど差がない。浮動小数点ユニットの効率は優秀なようである。逆に整数演算はMBPとの差が開く。これはコアの効率だけではなく、メモリアクセスなんかも影響しているんだろう。
それぞれの実行時間をiMacの結果を1としてログプロットした。面白いのはMBPとPi4とではだいたい倍ぐらい遅いだけ、という結果。MBPのコア数は2個なのでそのせいもあって近づいていると考えられるが、前回のシングルカーネルの結果に比べるとかなり差が圧縮されている。とくにほぼ倍精度浮動小数点演算だけのひとつめのベンチではほとんど差がない。浮動小数点ユニットの効率は優秀なようである。逆に整数演算はMBPとの差が開く。これはコアの効率だけではなく、メモリアクセスなんかも影響しているんだろう。
よっつめの固有値計算でPi3が極端に遅くなっているのはよくわからない。計算にまつわる部分でページアウトが発生した様子はないんだけど、CPU性能の差だけでは説明がつかないように思える。
ちなみに、複数のKernelによる並列計算は色々な制限がある。ParallelMapやParallelTableは独立なKernelによらなくても並列化できると思うんだけど、依存性の検出が難しいのか、オーバーヘッドの大きな仕様になっている。Parallelizeもほんとうに並列化してほしいFullSimplifyなどの式の変形には使えない。一方で、例えばFourierはFFTを使う部分で単一KernelでもThreadを増やしてCPUコアを全部使うようになっている。Parallelなんとかの関数グループはKernelに共通するシンボルを扱う場合は非常に難しい。たとえそれぞれのkernelが値を書き換えない場合でも、うまくいかないことがある。まだよくわからない。
これをみると、Mathematicaの実行性能だけでいえば、Raspberry Pi4は2010年ごろのMacBook ProやiMacの最下位機種と同等の性能になってきた、と言える。そんなのだけで比べるなよ、という人がいるだろうけど、直近の僕の興味はそこにあった。結論として言うと、
「Raspberry Pi 4のMathematicaは十分使い物になる」
ここでもう一度整理して、Rasbperry Pi OSでMathematicaを動かす場合に、どういう方法が一番いいのか試してみようと思う....
本来のRaspberry Piの使い方の想定というのは、こういうものだった。
こういうスタンドアロンな使い方をしている人はたぶん大勢いるだろう。特にRaspberry Pi以外にコンピュータを持っていない子供たちはこうする以外に方法がない。そしてこれで十分動くようにRaspberry Piは設計されているので、普通のパソコンに比べればちょっと遅い、という以外は全く問題がない。
ところが、子供たちだけではなく、僕みたいにRaspberry Piを安価なlinuxマシンとして使おうという大人が現れて、群がるようになってきた。そういう大人たちはすでにパソコンを持っていて、Raspberry Pi専用にディスプレイやキーボードやマウスを用意するというのは邪魔なだけでパソコンから使えるようにしようと考えた。
最初はリモートログインで、パソコンのターミナルからRaspberry Pi側のShellを起動していたけど、大人たちはmacOSやWindowsのGUIに慣れてしまっていて、Shellだけでは煩わしく感じた。そこで次にやるのがVNCである。
しかしVNCはディスプレイ画面を画像情報としてパソコンに常時流す必要がある(もちろん全画素を送るのではなくいろいろな圧縮をした上でやりとりしている。上の絵のRFBPはRemote Frame Buffer Protocolでそのとりきめに従っている。ちなみにXウィンドウのクライアントサーバの位置づけとVNCのそれとでは逆になっているような感じがする。ややこしい)。パソコンにとってネットワークトラフィックや表示に関するオーバーヘッドは大したことはないけど、Raspberry Piにはそこそこ重い。Raspberry PiでLチカやエディタを動かすぐらいなら問題なはいけど、Raspberry Piのコアを使い倒そうとするとVNCは邪魔な存在と言える。
Raspberry Piの標準OSであるRaspberry Pi OS(長いな。旧Raspbian)はGUIにX11ウィンドウシステムを使っている。さっきから絵に描いているように、X11サーバがディスレイへの表示、キーボードやマウスからの入力(Xイベントという)処理を一括してやっている。入出力の必要なアプリケーションはXクライアントとして、X11サーバに依頼する、という形をとる。このやりとりのしかたはXプロトコルといって非常にシンプルな手順に従っている。
X11サーバをパソコン側で動かす、ということも可能である。こうすればVNCは使わずに済む。
またXウィンドウシステムでは、ディスプレイマネジャもネットワーク上のどこにあってもいい、ということになっている。
今の多くのパソコンOSではウィンドウサーバとディスプレイマネジャは一体化しているけど、Xプロトコルの場合はディスプレイマネジャとの通信もXプロトコルを使うので、こういうことが可能になる。ここまでくると、Raspberry Pi側はshellを起動してコマンドラインで使うのと、少なくともプロセス数だけで比べれば大して変わらなくなって、Raspberry Pi側の仕事は楽になるはずである。
いや、楽になるはずだった。ところがあんがいそうではない。何がボトルネックかというと、Xプロトコルは設計が古き良き時代の、セキュリティの心配なんて誰も考えもしなかった頃に作られたものだった。せいぜいxhostで接続可能なホストを制限したり、xauthで権限を設定したり、という程度で、ネットワークには裸のXプロトコルが流れていた。
その後、セキュリティの厳しい時代になって、それはないだろ、ということに当然なった。Xプロトコルを暗号化しようという話が始まった。ところがもともとそんなことを考えないで作られたので、始めてみると思わないところに穴があいたり、それを塞いでいるうちにセキュリティの概念が厳しくなったりして、どんどん後追い後追いになっていった。複雑で効率が悪い、どっかのスラム街のようになっていった。
そして、スッパリ諦めた。こだわりなく諦めるというのは、実はすごく偉い。どこぞの誰とかとはそもそも大きく違うところである。Xプロトコルを堅牢にするのではなく、sshをトンネルに使おう、というわけである。
そのおかげで、認証やその設定が非常に複雑になっていたのが、sshの設定さえできていればそれでよくなった。暗号化したXプロトコルは非常に重くなったが、sshの通信効率がいいためにトンネルしてもかえって反応がいい、ということになった。すばらしい。
macOSの場合、ターミナルを開いて
$ ssh -Y decafish@betelgeuse.localとログインする。ここでbetelgeuseというのはLAN内のRaspberry Piのホスト名で、decafishはそのユーザ名である。この「-Y」というオプションがミソで、Xプロトコルを流すよ、という意味である。「-X」というのもあるらしい。クライアントの信用度の違いと、実装の歴史的な違いがあるらしい。
また、このためには/etc/ssh/sshd_configの中に
X11Forwarding yesという記述が必要になる。
これでリモートログインして、Xプロトコルを使うコマンドを実行すると、macOS側で、XQuartz(X11のmacOSの専用実装。ディスプレイマネジャは原則としてはmacOSのウィンドウマネジャに付随したAqua(quartz-wmというコマンドで、実際の調停はOS本体のウィンドウマネジャに依頼する)が使われる。Aquaがデザインの名前なのか、ウィンドウマネジャまで包含するのか、よくわからない)が自動的に起動して、macOSのlook-and-feelになるべく近くなるような形で動作するようになっている。
面白いのは、Rspberry Pi側でのDISPLAY変数が
$ echo $DISPLAY localhost:10.0となっていて、ローカルにXサーバがあるときと同じになる。まあ、当然と言えば当然だけど、Xプロトコルを暗号化しようとしていた頃はこのDISPLAY変数の設定も非常に複雑だった。ちなみにssh接続ごとにDISPLAY番号は増えていく。つまり、最終的には同じXサーバに繋がるんだけどsshトンネルが違うと違うディスプレイだとみなされるようである(直接繋がった物理ディスプレイにはlocalhost:0.0となって、まさか10台も繋がないだろう、というのが前提の番号付けになっている)。
ちなみに、Xquartzは最終リリースがもう4年前で、コードで言えば実質的に7年ほど前のがそのまま使われている。放置プレイと言っていい。まあ、X11そのものも充分枯れていてsshをトンネルすると決断したあと、基本的な考え方に変化はない。売り物のソフトウエアではユーザから金を巻き上げるために盛んにバージョンアップする必要があるけど、40年近い歴史のあるXでは、完成された部分に手を入れる必要はない。
ということで、Mathemtica以外のプロセスをなるべく減らして、Mathematicaだけをぶん回したらどうなるか、というのを試してみた。まずそれぞれでコア数に比例したMathemetica Kernelを起動する。
In[1]:= LaunchKernels[]とすると、例えばiMacでは6コア持っているので
このあと4つの計算をさせて実行時間を比較した。どれもKernelを使い倒すものにした。まずひとつめは
mlength[z_] :=Length[FixedPointList[#^2 + z &, z, 20, SameTest -> (Abs[#] > 2 &)]]
AbsoluteTiming[ParallelTable[ mlength[x + I y], {y, 0, 1, 0.002}, {x, -2, 1, 0.002}]][[1]]
これはMathematicaのドキュメントにあるMandelbrot集合を750k点について計算するもの。メモリ上で6MB消費する。これだとページアウトするほどではないけど、CPUのキャッシュには収まらない。ParallelTableでKernelに並列に割り当てる。ふたつめもドキュメントにある
f1[n_]:=Length[FactorInteger[(10^n-1)/9]] AbsoluteTiming[Parallelize[Map[f1, Range[10, 70]]]][[1]]1が並ぶ整数を素因数分解してその素因数の数を求める。桁数が増えると急速に時間がかかる。多倍精度整数の計算がどのくらい並列化できるか、にかかる。これもParallelizeで並列化している。
みっつめは
AbsoluteTiming[
ParallelSum[(-1)^n (4 n)! (1123 + 21460 n)/(882^(2 n + 1) (4^n (n!))^4),
{n, 0, 4000}]][[1]]
有名なラマヌジャンの$\pi$の値を計算する級数を途中まで計算する。$n$を$\infty$まで指定するとMathematicaはこの式を知っているらしくて瞬時に結果を返してしまうので、途中で切った。これも多倍精度の有理数の計算になる。よっつめは
AbsoluteTiming[Module[{a,b,m},
SeedRandom[1];
a=RandomReal[{},{420,420}];
b=DiagonalMatrix[RandomReal[{},{420}]];
m=a.b.Inverse[a];
ParallelDo[Eigenvalues[m],{50}]
]]
][[1]]
という、標準ベンチマークにあった巨大な行列の固有値を計算するもので、ParallelDoで並列化してる。この4つをiMac、MacBook Pro、Raspberry Pi 4B、Raspberry Pi 3Bで比較した。この4つだけなら、Xウィンドウは必要なく、リモートシェルだけでいいんだけど、そこは僕の本来の目的に沿うようなベンチにするため。それはそれとして、結果がこれ
よっつめの固有値計算でPi3が極端に遅くなっているのはよくわからない。計算にまつわる部分でページアウトが発生した様子はないんだけど、CPU性能の差だけでは説明がつかないように思える。
ちなみに、複数のKernelによる並列計算は色々な制限がある。ParallelMapやParallelTableは独立なKernelによらなくても並列化できると思うんだけど、依存性の検出が難しいのか、オーバーヘッドの大きな仕様になっている。Parallelizeもほんとうに並列化してほしいFullSimplifyなどの式の変形には使えない。一方で、例えばFourierはFFTを使う部分で単一KernelでもThreadを増やしてCPUコアを全部使うようになっている。Parallelなんとかの関数グループはKernelに共通するシンボルを扱う場合は非常に難しい。たとえそれぞれのkernelが値を書き換えない場合でも、うまくいかないことがある。まだよくわからない。
これをみると、Mathematicaの実行性能だけでいえば、Raspberry Pi4は2010年ごろのMacBook ProやiMacの最下位機種と同等の性能になってきた、と言える。そんなのだけで比べるなよ、という人がいるだろうけど、直近の僕の興味はそこにあった。結論として言うと、
「Raspberry Pi 4のMathematicaは十分使い物になる」
2020-07-26 22:16
nice!(0)
コメント(1)


F[x,y]={(-2 x+2 y+28)/(2 x^2-4 x y-28 x+2 y^2+24 y),(2 x-2 y-24)/(2 x^2-4 x y-28 x+2 y^2+24 y)}
なる写像による c;x^2-2 x y-28 x+y^2+24 y+191=0
の像 F(c) を 多様な発想で求めて下さい;
● F(c)∩Z^2 を求めて下さい;
[無論 其の導出法をも激白し]
c の 君の名は;___ ___ __
F(c)の 君の名は;___ ___ __
モシ 双曲線が 出現したなら 漸近線をも 無論導出願います;
by nbmath (2020-09-23 22:55)