macOSからPi Picoを使う - その9 [Pi Pico]
Pi Pico関連の記事が増えて本家Raspberry Piとは話の要点とするところが違ってしまったのでPi Picoの「マイカテゴリ」を作った。「Pi Picoカテゴリ」はハードウェア制御の話が中心で、たぶん本家「Raspberry Piカテゴリ」はunixとその周辺の話題(例えばMathematica on Raspberry Piとか)になる。まあ、半分ボケたジジイのすることなのであっという間に忘れてごちゃごちゃになるような気もするけど。
ところで「マイカテゴリ」はフラットで階層化できないので、どんどん長くなってしまう。まあ、カテゴリ分けはせいぜい古い記事を参照するときの分類用にしか使えなくて、僕の他にはあまり役に立たないかも。
まあそれはいいとして、前回まででマルチコアの起動の仕方と排他制御用のモジュールを見てきた。なんとなくわかったけど、普通の仮想記憶を持ったOSみたいにthread poolが用意されてコアを意識しなくてもプログラムできて効率よく実行される、というふうにはPi Picoではならない。プログラムはコアに縛られるので、それを頭に入れておく必要がある....
割り込みで書くとポーリングの必要がなくなるけど、割り込み処理ルーチンではできることが限られるので、あんがい難しいバグを生みやすい。というか、僕は若いころunixのsignalみたいな高水準の割り込みでさえ何度も痛い目に会ったので、なるべく割り込みを使わずに済ますように学習してしまった。
RP2040のspinlockやFIFOの操作は1クロックで処理できるのでポーリングのオーバーヘッドは低く、わざわざ割り込みで書いて苦労するよりすなおにポーリングして、割り込みはやはりループの底の方での非常にタイミングクリティカルなところにだけ使った方がいいような気がする。
僕はデータがFIFOに入るなら(つまり全部で32バイトにおさまるなら)FIFOをなるべくblockingなしで使った方がデッドロックの心配をする必要がない分精神衛生上好ましいと思うし、いつもそうしている。Pi PicoではA/Dは3本しか自由には使えないし、バイナリデータをいっときに大量に流すということもないので、FIFOで済まない場合というのは案外多くないような気もする。
作業分担としてはさっきも書いたようにcore0はUSBと上位作業に専念させて、core1でGPIOなどのアクセスをする。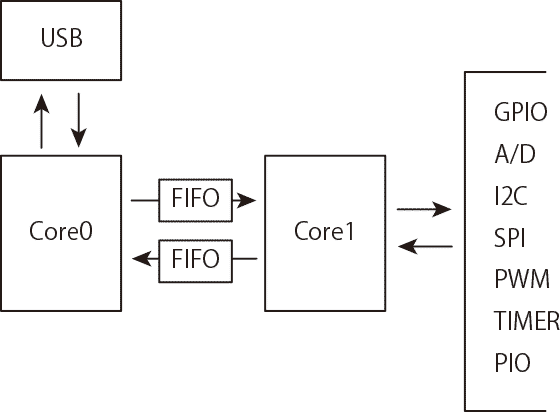 どちらのコアも中はループを回して
どちらのコアも中はループを回して
こうすると
FIFOは通信とは言え同じSoCチップの中なので、実質的にコア内部と変わらない。従ってそこでのエラーを考慮する必要はない。従ってcore1からcore0へのレスポンスの必要のない動作は何も返さないことにする。core1からcore0へ返すのは
また、もしcore0がFIFOに書くときにcore1が読み残したデータがあると、これはcore0の要求にcore1が追いついていないということなので、core1の読み込みを待ったりせずに、USBを経由してホストにエラーとして報告して、もっと処理密度を下げるように依頼する。
core1側での処理が長い場合、例えば外部の信号をポーリングするとか、ユーザを待たせる可能性があるほど長い場合、core0側がtimeoutを指定してある期間以内に変化がなければ、core0側から無いという情報を返させるような処理にしたほうがいいかもしれない。生存確認用のハートビート信号みたいなものである。その場合core0の命令はホストからの要求と1対1には対応しなくなる。しかしその場合でもやはり順番が入れ替わることはないのでこのモデルのままで問題ない。
あとは作業バランスで、stdioの実態であるTinyUSBの負荷があまり大きくなければ、core0側の作業量が少ないので例えば
ただし、今回の話は僕ならこうする、というだけで、Pi Picoでマルチコアを使うならこうした方がいい、あるいはこうすべきだ、なんていうものではない。こんなことをする人もいるんだな、ぐらいに思っていて欲しい。
ところで「マイカテゴリ」はフラットで階層化できないので、どんどん長くなってしまう。まあ、カテゴリ分けはせいぜい古い記事を参照するときの分類用にしか使えなくて、僕の他にはあまり役に立たないかも。
まあそれはいいとして、前回まででマルチコアの起動の仕方と排他制御用のモジュールを見てきた。なんとなくわかったけど、普通の仮想記憶を持ったOSみたいにthread poolが用意されてコアを意識しなくてもプログラムできて効率よく実行される、というふうにはPi Picoではならない。プログラムはコアに縛られるので、それを頭に入れておく必要がある....
9.4 multicoreをどうやって使うか
共有メモリ領域の変数が両方のコアで確定しているとする。そこを片方のコアが書いてもう一方が読むような場合mutexが一個あれば十分である。更新されたかどうかは共有メモリ上のフラグにしてもいいし、FIFOにその旨のメッセージを入れてもいい。どちらにしても定期的なポーリングは必要である。割り込みで書くとポーリングの必要がなくなるけど、割り込み処理ルーチンではできることが限られるので、あんがい難しいバグを生みやすい。というか、僕は若いころunixのsignalみたいな高水準の割り込みでさえ何度も痛い目に会ったので、なるべく割り込みを使わずに済ますように学習してしまった。
RP2040のspinlockやFIFOの操作は1クロックで処理できるのでポーリングのオーバーヘッドは低く、わざわざ割り込みで書いて苦労するよりすなおにポーリングして、割り込みはやはりループの底の方での非常にタイミングクリティカルなところにだけ使った方がいいような気がする。
僕はデータがFIFOに入るなら(つまり全部で32バイトにおさまるなら)FIFOをなるべくblockingなしで使った方がデッドロックの心配をする必要がない分精神衛生上好ましいと思うし、いつもそうしている。Pi PicoではA/Dは3本しか自由には使えないし、バイナリデータをいっときに大量に流すということもないので、FIFOで済まない場合というのは案外多くないような気もする。
9.4.1 動作モデル
Pi Picoでなるべくロックを使わないようにしてふたつのコアを同時に使うことを考える。作業分担としてはさっきも書いたようにcore0はUSBと上位作業に専念させて、core1でGPIOなどのアクセスをする。
- core0はUSBを監視してホストからの要求をチェックする
- ホストから要求があると、それを解釈、作業分解する
- 書き込み用FIFOにデータが残っていないことを確認する
- FIFOを経由してcore1へ命令として送る
- core1はFIFOを監視して命令が来たら作業を行い、その結果をFIFOに書く
- core0はFIFOを読んで結果を集約する
- 集約した結果をUSB経由でホストに返す
- core0のUSB監視とFIFOの読み書きはすべてブロックなし
- core1側はFIFOをブロック付きで読み込む
- FIFOから何か来ればその作業をする
- 結果をFIFOにブロック付きで書く
- どちらのコアもループ1回分はUSBのフレーム周期(1msec)より十分短くする
- ループ内で割り込みは利用しない
こうすると
- mutexが不要(FIFOがその代わり)
- 内部でのデータ消失がない
- ホストらかの要求に対するレスポンスは速い
FIFOは通信とは言え同じSoCチップの中なので、実質的にコア内部と変わらない。従ってそこでのエラーを考慮する必要はない。従ってcore1からcore0へのレスポンスの必要のない動作は何も返さないことにする。core1からcore0へ返すのは
- 結果が必要な命令
- 外部ハードウェア上のエラー
また、もしcore0がFIFOに書くときにcore1が読み残したデータがあると、これはcore0の要求にcore1が追いついていないということなので、core1の読み込みを待ったりせずに、USBを経由してホストにエラーとして報告して、もっと処理密度を下げるように依頼する。
core1側での処理が長い場合、例えば外部の信号をポーリングするとか、ユーザを待たせる可能性があるほど長い場合、core0側がtimeoutを指定してある期間以内に変化がなければ、core0側から無いという情報を返させるような処理にしたほうがいいかもしれない。生存確認用のハートビート信号みたいなものである。その場合core0の命令はホストからの要求と1対1には対応しなくなる。しかしその場合でもやはり順番が入れ替わることはないのでこのモデルのままで問題ない。
あとは作業バランスで、stdioの実態であるTinyUSBの負荷があまり大きくなければ、core0側の作業量が少ないので例えば
- ソフトウェアPID制御などはPIDの計算をcore0で、瞬時値の制御をcore1で
- core1側では無単位で、core0側で物理量に変換
ただし、今回の話は僕ならこうする、というだけで、Pi Picoでマルチコアを使うならこうした方がいい、あるいはこうすべきだ、なんていうものではない。こんなことをする人もいるんだな、ぐらいに思っていて欲しい。
2021-06-17 20:24
nice!(0)
コメント(0)


コメント 0