ポリゴンレンダラ - その9 [プログラミング]
前回vDSPにあるFFT以外の関数群をおさらいした。ごちゃごちゃと雑多なものが含まれている。vDSPのFFTは以前驚くほどのスピードを出していたが、それ以外の関数が同じくらいのパフォーマンスがでるかどうかは試していないのでわからない。普通に考えれば単純計算を実行する関数が多いのでFFTほどのパフォーマンス差は出ない、と考えるのが素直な姿勢だろう。
パフォーマンスの単純比較をする前に、今回のポリゴンレンダラに使う計算のうち、どの部分にどんなvDSPの関数が使えそうかをざっくりと見てみることにする。
これは4×4マトリクスとベクトルの積の計算だけど、vDSPにマトリクスとベクトルの積をやる関数は無い。
しかも呼び出しのオーバーヘッドを考えると、どのみち4×4は小さくてvDSPのメリットが出ない可能性がある。
同次座標変換を行う座標点がN個あるとすると、4×4マトリクスとベクトルの積をN回やることになるが、これは4×4マトリクスとN×4マトリクスの積と見なしてもよい。
つまり(わかりやすさのために、vと書いたのを横ベクトルであるとして、今回だけは縦横のベクトルをちゃんと区別して書くことにすると)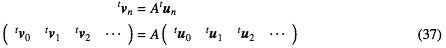 とするとvDSP関数1回の呼び出しですむことになる。
とするとvDSP関数1回の呼び出しですむことになる。
ところがこの場合、N×4マトリクスは横に長いマトリクスで、ひとつの同次座標すなわちベクトルは縦、つまりカラム方向に並ぶことになる。ところが座標をフラットに並べた場合はベクトルは(Cの配列だとすると)横方向になって、マトリクスとみた場合転置する必要がある。Nが大きくなるとこの手間は馬鹿にできない。
そのかわりにかけ算の向きをかえてAのほうを転置すればいい。つまり とすればいい。この場合は小さなマトリクスAだけを前もって転置しておけばいい、ということになる。
とすればいい。この場合は小さなマトリクスAだけを前もって転置しておけばいい、ということになる。
昔CLAPACKを使おうとして似たようなことをしたあげくにぐちゃぐちゃになって投げ出した。気をつけないといけない。
どういうのが必要かというと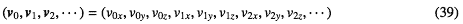 を扱う、ということにすればいい。
を扱う、ということにすればいい。
どのみち今回は、ポリゴンと座標をわけてしまったので、vDSPに渡すときはコピーを作らないといけない。これは大きなオーバーヘッドになる。
このオーバーヘッドをかけてもvDSPを使うべきかどうかは測定して決めるしかない。
内積を要素に分けて書くと である。
である。
これは二つの部分
これでほんとに速くなるかどうかはやっぱり測定するしかない。
従ってこれも何段かのステップに分けないといけない。内積を使ってもいいけど要素をそれぞれ2乗するvDSP関数はあるので
さらにその値で元の要素を割るのは、またストライド3のベクトルとみなしてx、y、zごとに配列の割り算をすることになる。
式通りに直接書いてコンパイルするのに較べて非常に煩わしくて、数倍くらい速くならないとvDSPを使うメリットはなかなか見いだしにくい。まあ、これも測定するしかない。
規格化されていない法線nは、ポリゴンの最初のみっつの頂点の座標p0、p1、p2から として計算することにする。4頂点以上持っているポリゴンも、最初の約束で全部の頂点が一つの平面に乗っていることにしたのでこれでいい。ベクトル積は
として計算することにする。4頂点以上持っているポリゴンも、最初の約束で全部の頂点が一つの平面に乗っていることにしたのでこれでいい。ベクトル積は
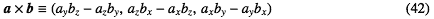 でまじめに計算する。
でまじめに計算する。
ベクトル積にvDSPを使えるようにするのは要素の並べ替えが必要になって、けっこうたいへん。中身は単純計算でしかないからFFTのような計算量を減らす余地がないので、そこまでしてvDSPを使ってほんとに速くなるのか、というのはかなり疑問。まあ、実装のプライオリティは低いな。
パフォーマンスの単純比較をする前に、今回のポリゴンレンダラに使う計算のうち、どの部分にどんなvDSPの関数が使えそうかをざっくりと見てみることにする。
7.2 今回どれが使えるか
7.2.1 同次座標変換にvDSPを使う
まず、ひとつは同次座標変換。これは4×4マトリクスとベクトルの積の計算だけど、vDSPにマトリクスとベクトルの積をやる関数は無い。
しかも呼び出しのオーバーヘッドを考えると、どのみち4×4は小さくてvDSPのメリットが出ない可能性がある。
同次座標変換を行う座標点がN個あるとすると、4×4マトリクスとベクトルの積をN回やることになるが、これは4×4マトリクスとN×4マトリクスの積と見なしてもよい。
つまり(わかりやすさのために、vと書いたのを横ベクトルであるとして、今回だけは縦横のベクトルをちゃんと区別して書くことにすると)
ところがこの場合、N×4マトリクスは横に長いマトリクスで、ひとつの同次座標すなわちベクトルは縦、つまりカラム方向に並ぶことになる。ところが座標をフラットに並べた場合はベクトルは(Cの配列だとすると)横方向になって、マトリクスとみた場合転置する必要がある。Nが大きくなるとこの手間は馬鹿にできない。
そのかわりにかけ算の向きをかえてAのほうを転置すればいい。つまり
昔CLAPACKを使おうとして似たようなことをしたあげくにぐちゃぐちゃになって投げ出した。気をつけないといけない。
7.3 照明計算でvDSPを使う
照明計算のために、ベクトルの計算をしないといけない。どういうのが必要かというと
- 座標の引き算をして方向ベクトルや位置ベクトルを得る
- ベクトルの規格化
- ベクトルの内積
- ベクトル積
7.3.1 座標値の引き算
ベクトル同士の引き算もvDSPにはある。任意の長さの配列に対して使えるが、3次元座標、つまり長さ3の配列ごとにvDSP関数を呼んでいたら、呼び出しのオーバーヘッドの方が大きくなりそうである。vDSPを使うなら座標をずらっとならべてひとつのvDSP関数でいっぺんにやるべきであろう。 つまり一つの大きな配列どのみち今回は、ポリゴンと座標をわけてしまったので、vDSPに渡すときはコピーを作らないといけない。これは大きなオーバーヘッドになる。
このオーバーヘッドをかけてもvDSPを使うべきかどうかは測定して決めるしかない。
7.3.2 ベクトルの内積
内積もvDSP関数にある。でもやはり長さ3のベクトル一つ一つについてvDSP関数を呼ぶのはオーバーヘッドが大きい。これをいっぺんにやるのはどうするか。内積を要素に分けて書くと
これは二つの部分
- 要素ごとの積
- x、y、z要素の和
- 積の結果の長い配列をストライド3のベクトルとみなして
- xとyの要素を足す
- それにz要素を足す
これでほんとに速くなるかどうかはやっぱり測定するしかない。
7.3.3 ベクトルの規格化
ベクトルの規格化はvDSPにあっても不思議ではないという気がするんだけど、残念ながら無い。従ってこれも何段かのステップに分けないといけない。内積を使ってもいいけど要素をそれぞれ2乗するvDSP関数はあるので
- 要素の2乗を計算する
- x、y、zの組ごとに足す
- その値の平方根をとる
- 要素をその値で割る
void vvrsqrt ( double *, const double *, const int * );という関数はある。これを使えばいいんだけどvDSPと違ってストライドがとれず、詰った配列でないといけない。それに対応できるようにコーディングする必要がある。
さらにその値で元の要素を割るのは、またストライド3のベクトルとみなしてx、y、zごとに配列の割り算をすることになる。
式通りに直接書いてコンパイルするのに較べて非常に煩わしくて、数倍くらい速くならないとvDSPを使うメリットはなかなか見いだしにくい。まあ、これも測定するしかない。
7.3.4 ベクトル積
ポリゴンの法線ベクトルの計算でベクトル積を計算する必要がある。でも、法線ベクトルの計算は最初に一度しかやらないのでがんばってもあまり意味はない。できるところだけか、あとで同じことをする必要がある場合だけvDSPを使うことにしたほうがいい。規格化されていない法線nは、ポリゴンの最初のみっつの頂点の座標p0、p1、p2から
ベクトル積にvDSPを使えるようにするのは要素の並べ替えが必要になって、けっこうたいへん。中身は単純計算でしかないからFFTのような計算量を減らす余地がないので、そこまでしてvDSPを使ってほんとに速くなるのか、というのはかなり疑問。まあ、実装のプライオリティは低いな。
2013-05-10 23:36
nice!(0)
コメント(0)
トラックバック(0)


コメント 0