Apple Siliconで動作するエミュレータの常設化? [日常のあれやこれや]
先日M1のFirestormコアはマイコロコードを使っていないと考えた。そしておそらく32ビット命令は実行できない。しかしARM版のWindows10は動く(ただしQEMU上)そうなので、M1ではarm64命令をいちおう全部実行できるようになっているんだろう(QEMUをXcode12ですべてコンパイルしなおしたらわからんか。そうしたんだろうか)。
しかしそのとき考えたように、AppleはコンパイラからCPUからOSから全部取り仕切っているので、ARMの互換性にこだわる必要はない。ARMのライセンスはレベルがいくつかあってその詳細を理解してないんだけど、CPUとしてARMライセンスに依存しないといけない部分が残ってなければ、Appleは自分たちに都合の良いようにするだろう。これまでも後方互換性をあっさり捨ててきた。おかげで何度も泣かされたわけだけど。
昔のPowerPC上の68LC040(浮動小数点ユニットなしの68040)エミュレータから、Rosetta(x86_64上のPowerPC)と、今回のRosetta2(ARM64上のx86_64)でCPU命令のエミュレーションはAppleの十八番(オハコ)になってる。マイクロコードを実装するのに比べたらソフトウェアエミュレータのほうが自由度が高くて複雑さや規模の問題も少ない。マイクロコードで互換性を取るのではなく、エミュレータで吸収する方があとあといいはずである。
エミュレータの実行コードの一番厳しい部分がL1キャッシュに収まってしまえば、もとはバスを隔てたソフトウェアだけど、マイクロコードにせまる効率が出るだろうし、一番内側のループがディスパッチャのバッファに収まれば、実質的に書き換え可能なマイクロコードと言ってもいいくらい(VAX11/780を思い出すな。ブートはまずマイクロコードをロードするところから始まった)。ずっとまえ68020の256バイトしかないキャッシュにFFTのループを僕が詰め込むことができたくらいだから、630エントリ(実行コードで2520バイト分)もあればけっこういろんなことができるはず。
エミュレータのオーバーヘッドを上回る高速化がCPUで可能なら命令セットを変更しても、すなわちARM64のさらなるRISC化か、あるいは逆にAppleが有用と考える命令の追加や置き換えになるけど、Appleなら迷惑のかかる範囲は少ないし、ユーザはむしろ歓迎するだろう。
まあ、もともとARM64はARM32とビットパターンレベルでは互換性がないしARM32にあった条件実行なんかも捨てていて(捨てないと32ビット固定長におさまらなかったらしい)、ARM64だけだと十分筋肉質だと言えるので、x86と違ってサポートする命令を減らしたからと言って面積が減るようなものでもなさそうである。でもエミュレータを単にアーキテクチャの橋渡しとして使い捨てるのではなくて、ハードウェアをサポートするもっとも低レベルのソフトウェア要素にする、というのは十分ありそうな気がする。iMacに32コアなんて話もあるぐらいなので、Firestormコアのパフォーマンスを落とさずにその面積を減らす、というのはばきばきに検討してるはずだと思う(32コアを使い倒せるプログラミングも並大抵じゃない気がするけど)。
なんかこないだから僕はM1のことばかり気にしてるな。酸っぱいはずじゃなかったっけ。
しかしそのとき考えたように、AppleはコンパイラからCPUからOSから全部取り仕切っているので、ARMの互換性にこだわる必要はない。ARMのライセンスはレベルがいくつかあってその詳細を理解してないんだけど、CPUとしてARMライセンスに依存しないといけない部分が残ってなければ、Appleは自分たちに都合の良いようにするだろう。これまでも後方互換性をあっさり捨ててきた。おかげで何度も泣かされたわけだけど。
昔のPowerPC上の68LC040(浮動小数点ユニットなしの68040)エミュレータから、Rosetta(x86_64上のPowerPC)と、今回のRosetta2(ARM64上のx86_64)でCPU命令のエミュレーションはAppleの十八番(オハコ)になってる。マイクロコードを実装するのに比べたらソフトウェアエミュレータのほうが自由度が高くて複雑さや規模の問題も少ない。マイクロコードで互換性を取るのではなく、エミュレータで吸収する方があとあといいはずである。
エミュレータの実行コードの一番厳しい部分がL1キャッシュに収まってしまえば、もとはバスを隔てたソフトウェアだけど、マイクロコードにせまる効率が出るだろうし、一番内側のループがディスパッチャのバッファに収まれば、実質的に書き換え可能なマイクロコードと言ってもいいくらい(VAX11/780を思い出すな。ブートはまずマイクロコードをロードするところから始まった)。ずっとまえ68020の256バイトしかないキャッシュにFFTのループを僕が詰め込むことができたくらいだから、630エントリ(実行コードで2520バイト分)もあればけっこういろんなことができるはず。
エミュレータのオーバーヘッドを上回る高速化がCPUで可能なら命令セットを変更しても、すなわちARM64のさらなるRISC化か、あるいは逆にAppleが有用と考える命令の追加や置き換えになるけど、Appleなら迷惑のかかる範囲は少ないし、ユーザはむしろ歓迎するだろう。
まあ、もともとARM64はARM32とビットパターンレベルでは互換性がないしARM32にあった条件実行なんかも捨てていて(捨てないと32ビット固定長におさまらなかったらしい)、ARM64だけだと十分筋肉質だと言えるので、x86と違ってサポートする命令を減らしたからと言って面積が減るようなものでもなさそうである。でもエミュレータを単にアーキテクチャの橋渡しとして使い捨てるのではなくて、ハードウェアをサポートするもっとも低レベルのソフトウェア要素にする、というのは十分ありそうな気がする。iMacに32コアなんて話もあるぐらいなので、Firestormコアのパフォーマンスを落とさずにその面積を減らす、というのはばきばきに検討してるはずだと思う(32コアを使い倒せるプログラミングも並大抵じゃない気がするけど)。
なんかこないだから僕はM1のことばかり気にしてるな。酸っぱいはずじゃなかったっけ。
肉眼で回転運動に対するストロボ効果はあるのか? [日常のあれやこれや]
さっき「チコちゃんに叱られる」の再放送を見ていたら、「走行中のタイヤが止まったり逆回転に見えるのはなぜ?」の答えに「1秒間に4〜5枚の絵しか見てないから」というのがあった。これは普通は、いわゆるストロボ効果によるものがほとんどで、つまりカメラでの動画か、間欠照明があった場合にはっきり見える。物理的には折り返しノイズの具体例である。
番組ではそれを人間の目の特性だけで説明していた。それはおかしいと思う。
直線運動に対しては目のサッケード運動(衝動性眼球運動)と連動したとき、網膜上の画像が固定されて止まって見えることがある。これは直線運動している物体に注目してはっきり見ようと眼球や頭を意識的に動かすことで目のモーションブラー を止めるのや、鶏が歩くとき首を前後に振る動作と同じである。サッケード運動はすごく速くて像運動と連動したときは無意識的なので、止まって見えると印象に残りやすい。でもサッケードは意識的にはできないのでいつも見える、ということにはならない。
しかし眼球には光軸周りの回転の自由度はない。眼球運動用の筋肉は光軸に沿った方向にしかないし、もし回転したら太い視神経が捩れてしまう。視神経は脳までの距離が短いけど、やっぱり最終的には化学的な作用なので応答速度はせいぜい10msecぐらいのはずだし、また1つの視神経はフォトン1個に反応できるとは思えないので、ある程度の積分時間が必要なはずである。そして目にはCCDやC-MOSイメージャの電荷蓄積タイミング制御のような機能はない。したがってそれ以下の時間分解能は目にはない。つまり、回転している物体は、脳で処理される前に網膜上の画像としてボケる。
だから、カメラ越しではなく、間欠照明もない場所での肉眼で回転運動に対してストロボ効果が発生するとは思えない。肉眼で見えたというのはどこかに発光が電源(あるいはそのインバータ)に同期してしまうナトリウムランプや蛍光灯があることに気が付いてなかったのではないか、と思う。
もし、そうではない、という人がいたらコメントください。例えば「私の脳は網膜像のデコンボリューションができる」とか。
でも最近チコちゃんあまり面白くない。マンネリはしょうがないか。でも「逆連想ゲーム」は退屈で、どうせなら「とことん妄想ゲーム」とかのほうがいい。いやそれは、小さいおともだちに見せられなくなるか。
番組ではそれを人間の目の特性だけで説明していた。それはおかしいと思う。
直線運動に対しては目のサッケード運動(衝動性眼球運動)と連動したとき、網膜上の画像が固定されて止まって見えることがある。これは直線運動している物体に注目してはっきり見ようと眼球や頭を意識的に動かすことで目のモーションブラー を止めるのや、鶏が歩くとき首を前後に振る動作と同じである。サッケード運動はすごく速くて像運動と連動したときは無意識的なので、止まって見えると印象に残りやすい。でもサッケードは意識的にはできないのでいつも見える、ということにはならない。
しかし眼球には光軸周りの回転の自由度はない。眼球運動用の筋肉は光軸に沿った方向にしかないし、もし回転したら太い視神経が捩れてしまう。視神経は脳までの距離が短いけど、やっぱり最終的には化学的な作用なので応答速度はせいぜい10msecぐらいのはずだし、また1つの視神経はフォトン1個に反応できるとは思えないので、ある程度の積分時間が必要なはずである。そして目にはCCDやC-MOSイメージャの電荷蓄積タイミング制御のような機能はない。したがってそれ以下の時間分解能は目にはない。つまり、回転している物体は、脳で処理される前に網膜上の画像としてボケる。
だから、カメラ越しではなく、間欠照明もない場所での肉眼で回転運動に対してストロボ効果が発生するとは思えない。肉眼で見えたというのはどこかに発光が電源(あるいはそのインバータ)に同期してしまうナトリウムランプや蛍光灯があることに気が付いてなかったのではないか、と思う。
もし、そうではない、という人がいたらコメントください。例えば「私の脳は網膜像のデコンボリューションができる」とか。
でも最近チコちゃんあまり面白くない。マンネリはしょうがないか。でも「逆連想ゲーム」は退屈で、どうせなら「とことん妄想ゲーム」とかのほうがいい。いやそれは、小さいおともだちに見せられなくなるか。
FirestormコアのALU [日常のあれやこれや]
Apple SiliconのM1のブロックダイアグラムの推測を見た先日の記事で「それ以外のALUはマイクロコードで実行か」と書いたけど、おそらくそれは間違いで、マイクロコードの必要はないな。FirestormコアにはALUが8個あるけど非対称で、整数の割り算や掛け算のできないユニットがある。つまりそのALUはフラグ操作とシフトと足し算しかできないので掛け算割り算はマイクロコードになってるのかと思った。
でもよく考えると(よく考えないでも)ディスパッチユニットに収まった時点で演算の中身はわかっている。その命令に関係するレジスタ名が割り当てられて実行可能になったとき、演算の内容によってALUを選べばいいだけだもんな。それが塞がってた場合も実行起動条件の判断と同じだもんな。マイクロコードで面積を増やしても掛け算の頻度から考えて7つのALU全部が掛け算を実行している場面はほとんどありえないから、演算種類の出現頻度の比で何を実装するかを決めればいい。したがってFirestorm側はマイクロコードは使ってないということだ。
低電力消費のIcestormはどうなってるんだろ。割り算までできるやつと掛け算までと足し算だけとブランチユニットの4つでSIMDがひとつだけとか。それだけでは消費電力はせいぜい半分で、すごく違う、とかいうとこまでいかなそうだよな。これもマイクロコードにしたからと言って面積は小さくなるけど遅くなって1命令あたりの消費電力は上がるもんな。それぞれ4つのFirestormとIcestormがチップ面積比で3:1ぐらいでキャッシュサイズも12MBと4MBなので、それに比例するぐらいもっと違うのかな。並列デコーダや大量のrenamingバッファに比べたら足し算ALUの面積なんて、シフトができる必要もないので、たいしたことないかもしれない。
そもそもFirestormとIcestormで性能比と消費電力比はどのくらいなんだろうか。性能比:消費電力比=1だとクロックを落としたり場合によっては止めたりすれば同じで、作り分ける意味ないもんな。
いやいや、もうどうでもいい。MBPは買ったばっかりだし、会社で使ってた6コアiMacもうちに運んだし、しばらくM1 Macを買うことはないもんな。
え〜ん、M1 Macなんかいらないやい。きっと酸っぱいに決まってる。
でもよく考えると(よく考えないでも)ディスパッチユニットに収まった時点で演算の中身はわかっている。その命令に関係するレジスタ名が割り当てられて実行可能になったとき、演算の内容によってALUを選べばいいだけだもんな。それが塞がってた場合も実行起動条件の判断と同じだもんな。マイクロコードで面積を増やしても掛け算の頻度から考えて7つのALU全部が掛け算を実行している場面はほとんどありえないから、演算種類の出現頻度の比で何を実装するかを決めればいい。したがってFirestorm側はマイクロコードは使ってないということだ。
低電力消費のIcestormはどうなってるんだろ。割り算までできるやつと掛け算までと足し算だけとブランチユニットの4つでSIMDがひとつだけとか。それだけでは消費電力はせいぜい半分で、すごく違う、とかいうとこまでいかなそうだよな。これもマイクロコードにしたからと言って面積は小さくなるけど遅くなって1命令あたりの消費電力は上がるもんな。それぞれ4つのFirestormとIcestormがチップ面積比で3:1ぐらいでキャッシュサイズも12MBと4MBなので、それに比例するぐらいもっと違うのかな。並列デコーダや大量のrenamingバッファに比べたら足し算ALUの面積なんて、シフトができる必要もないので、たいしたことないかもしれない。
そもそもFirestormとIcestormで性能比と消費電力比はどのくらいなんだろうか。性能比:消費電力比=1だとクロックを落としたり場合によっては止めたりすれば同じで、作り分ける意味ないもんな。
いやいや、もうどうでもいい。MBPは買ったばっかりだし、会社で使ってた6コアiMacもうちに運んだし、しばらくM1 Macを買うことはないもんな。
え〜ん、M1 Macなんかいらないやい。きっと酸っぱいに決まってる。
Apple Silicon MacのFirestormコア [日常のあれやこれや]
ここを経由してここ を教えてもらった。そこにApple M1 SoCの高性能側のコアであるFirestormのブロックダイアグラムがあって、なかなか面白い。
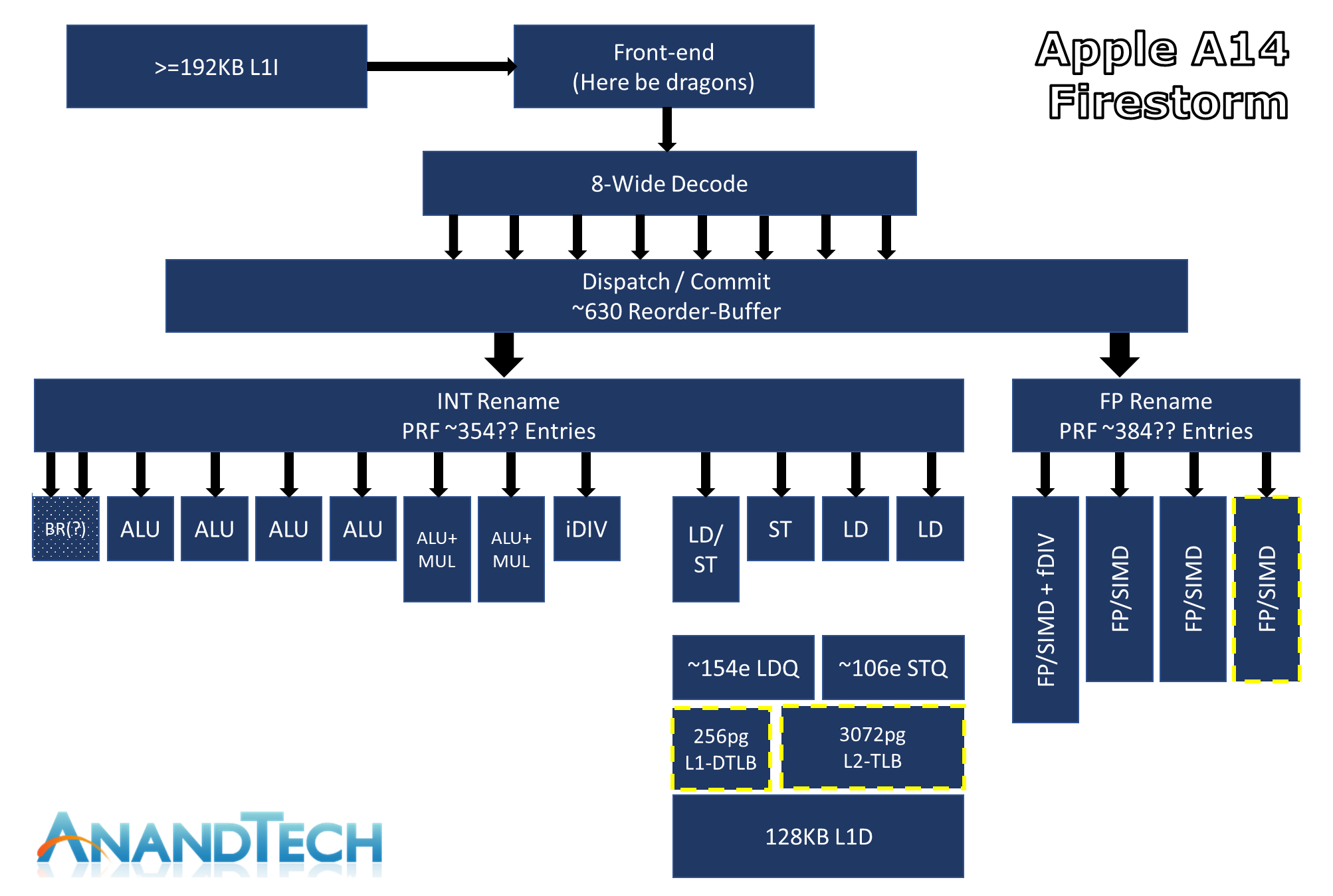 これだと8命令を同時にデコードできて、デコードした630個の命令の中から実行可能な命令を選び出せ(ディスパッチ)て、レジスタ名付け替え(Out-of-Order実行のキモの機構)が整数用に354エントリ浮動小数点用に384エントリあって、整数ALUが7つと分岐専用(?)ユニットがひとつ、そのうち整数の掛け算ができるのが2つと割り算までできるのが1つ(それ以外のALUはマイクロコードで実行か)、浮動小数点とベクタ演算のユニット(64ビット命令セットではスカラ浮動小数点もSIMDユニットが受け持つらしい。たしかに浮動小数点演算はヘビーでレイテンシも深くなりがちなのでALUに持たない方が簡単だな)が4つ、ロード/ストアユニットが4つとそれ用の深さ100以上のキューがそれぞれひとつずつ、それに192Kの命令用L1キャッシュと128Kのデータ用L1キャッシュと、L2キャッシュ用のTLBが3072ページぶんある(L2はコアに共通だったと思ったけど、それぞれTLBを持っててカチ合わないんだっけ?)、と描いてある。どこまでほんとなのかよくわからないけど、ディスパッチユニットのウィンドウサイズを測定したらしいデータを載せているので、そこそこ自信があるらしい。
これだと8命令を同時にデコードできて、デコードした630個の命令の中から実行可能な命令を選び出せ(ディスパッチ)て、レジスタ名付け替え(Out-of-Order実行のキモの機構)が整数用に354エントリ浮動小数点用に384エントリあって、整数ALUが7つと分岐専用(?)ユニットがひとつ、そのうち整数の掛け算ができるのが2つと割り算までできるのが1つ(それ以外のALUはマイクロコードで実行か)、浮動小数点とベクタ演算のユニット(64ビット命令セットではスカラ浮動小数点もSIMDユニットが受け持つらしい。たしかに浮動小数点演算はヘビーでレイテンシも深くなりがちなのでALUに持たない方が簡単だな)が4つ、ロード/ストアユニットが4つとそれ用の深さ100以上のキューがそれぞれひとつずつ、それに192Kの命令用L1キャッシュと128Kのデータ用L1キャッシュと、L2キャッシュ用のTLBが3072ページぶんある(L2はコアに共通だったと思ったけど、それぞれTLBを持っててカチ合わないんだっけ?)、と描いてある。どこまでほんとなのかよくわからないけど、ディスパッチユニットのウィンドウサイズを測定したらしいデータを載せているので、そこそこ自信があるらしい。
ARMの32ビットモードは歴史を抱えてて結構複雑になってるので、やっぱり32ビット命令は無視してデコードユニットを軽くして、そのぶんALUの数を増やしたんだろうなあ。ベクタレジスタは128ビット幅なのでx64の半分だけど、浮動小数点/SIMDユニットが4つとレジスタリネームが384エントリもあってそれが4コアあるので、FFTとかサイズ次第では爆速じゃないかなあ。
ALUはx64とARMで実質的に同じことをすればいいんだけど、こう見るとx64は命令長が可変だというだけですごく不利のような気がしてくる。M1みたいに古い命令はサポートしない、みたいなことはできなくて「自分の過去は全て責任を持つ」でないといけないのでよけい厳しいよなあ。
ユニットのレイテンシの違いや分岐命令でストールしたり、整数演算とSIMDがバランスよく並ぶなんてこともないだろうから、全部のALUとFP/SIMDユニットがいつも動いてるなんてことはないだろうけど、FirestormのInstructions per Clockのスループットは最大8命令ということで、これだとクロック同じでコア数同じでも性能5割増しとか十分あり得そうだよなあ。
LLVMコンパイラもAppleが仕切ってるわけだから、ハードウェアサポートしたくない命令を吐かないようにしてしまえばいいわけで、ARMの実行効率に寄与しない部分は全部剥ぎ取ることができる。Appleはやろうと思えばバリバリ筋肉質のコアにできる、ということだな。IntelやAMDに言わせれば「ずるい」ということになるけど。
なんか、買ったばかりのMacbook Proが、ぜんぜん使ってないところに電気を食ってるんじゃないかと思えてくるよなあ。
ARMの32ビットモードは歴史を抱えてて結構複雑になってるので、やっぱり32ビット命令は無視してデコードユニットを軽くして、そのぶんALUの数を増やしたんだろうなあ。ベクタレジスタは128ビット幅なのでx64の半分だけど、浮動小数点/SIMDユニットが4つとレジスタリネームが384エントリもあってそれが4コアあるので、FFTとかサイズ次第では爆速じゃないかなあ。
ALUはx64とARMで実質的に同じことをすればいいんだけど、こう見るとx64は命令長が可変だというだけですごく不利のような気がしてくる。M1みたいに古い命令はサポートしない、みたいなことはできなくて「自分の過去は全て責任を持つ」でないといけないのでよけい厳しいよなあ。
ユニットのレイテンシの違いや分岐命令でストールしたり、整数演算とSIMDがバランスよく並ぶなんてこともないだろうから、全部のALUとFP/SIMDユニットがいつも動いてるなんてことはないだろうけど、FirestormのInstructions per Clockのスループットは最大8命令ということで、これだとクロック同じでコア数同じでも性能5割増しとか十分あり得そうだよなあ。
LLVMコンパイラもAppleが仕切ってるわけだから、ハードウェアサポートしたくない命令を吐かないようにしてしまえばいいわけで、ARMの実行効率に寄与しない部分は全部剥ぎ取ることができる。Appleはやろうと思えばバリバリ筋肉質のコアにできる、ということだな。IntelやAMDに言わせれば「ずるい」ということになるけど。
なんか、買ったばかりのMacbook Proが、ぜんぜん使ってないところに電気を食ってるんじゃないかと思えてくるよなあ。
仕事で困ってること [日常のあれやこれや]
実は、僕はちょうど3年前、ある有名なレンズ設計用ソフトの営業とケンカしてそのソフトが使えなくなっていた(そんなの、いらねいやい!と、メールで啖呵を切った。「酸っぱいぶどう」そのまんまやがな)。ところが最近お客さんからその「レンズ設計用ソフト」で読めるデータをよこせと言われることがある。そのソフトの機能で、中身は読めないけど光線追跡したり、他の光学系の中に組み込んだりできる「ブラックボックス」というのがあって、そのデータを要求されるようになった。
昔だったら、ごめんなさい出せません、必要な計算はこちらでします、と言ったんだけど、最近それが通用しなくなってきた。データが出せないというと
特に米国では、光学素子のメーカは「ブラックボックス」にもなっていないナマのデータを提示するところも増えている。ガラスプレスの回折限界単玉非球面レンズなどは、設計よりも作る方がずっと難しいので、顧客の要求に答えられるところは積極的にそうしよう、ということだろう。
どうせ僕は多群ズームなんかの設計はしなくて、レンズ設計といっても仕事で必要なのはせいぜいガラスやプラの単玉非球面レンズで、それ以外は「レンズ設計ソフトウェア」の最適化ではできない、あるいは効率の悪い設計で、それがある意味僕のニッチでもある。従って汎用ソフトがないならないでそれほど困らない。そうでなければあとは汎用のエレメントを組み合わせるだけなので、光線追跡して評価ができれば十分である。
それにきっとソフトの営業では僕がブラックリストに入ってるだろうし。いや、もういちどライセンス受けたいといえば、ニコニコしながら売ってくれるだろうけど、それって、よけい悔しいなあ。ニコニコの顔の下に「ざまあ」と大書きしてあるようなもんだよなあ。
しかしすぐに
困ったなあ。
昔だったら、ごめんなさい出せません、必要な計算はこちらでします、と言ったんだけど、最近それが通用しなくなってきた。データが出せないというと
客:「では、どうやって設計したんだ?」 僕:「自分で書いて...」 客:「(なんだ素人か...)」という反応をされることが増えた。このエレメントの設計に最適化による収束計算は必要ない、と説明してもこれでたいていのお客さんはこれで話は終わり、という姿勢になる。
特に米国では、光学素子のメーカは「ブラックボックス」にもなっていないナマのデータを提示するところも増えている。ガラスプレスの回折限界単玉非球面レンズなどは、設計よりも作る方がずっと難しいので、顧客の要求に答えられるところは積極的にそうしよう、ということだろう。
どうせ僕は多群ズームなんかの設計はしなくて、レンズ設計といっても仕事で必要なのはせいぜいガラスやプラの単玉非球面レンズで、それ以外は「レンズ設計ソフトウェア」の最適化ではできない、あるいは効率の悪い設計で、それがある意味僕のニッチでもある。従って汎用ソフトがないならないでそれほど困らない。そうでなければあとは汎用のエレメントを組み合わせるだけなので、光線追跡して評価ができれば十分である。
それにきっとソフトの営業では僕がブラックリストに入ってるだろうし。いや、もういちどライセンス受けたいといえば、ニコニコしながら売ってくれるだろうけど、それって、よけい悔しいなあ。ニコニコの顔の下に「ざまあ」と大書きしてあるようなもんだよなあ。
しかしすぐに
社長&営業:「なんで客先に必要なデータが出せないんだ?」 僕: 「ソフトの営業と喧嘩しまして」なんてことになって、そうなると馬鹿野郎呼ばわり間違い無いよな。ごまかしててもすぐバレるよな。そもそもここにこうやって書いたらおしまいだもんな。
困ったなあ。
Apple Silicon Macのベンチマーク [日常のあれやこれや]
Apple Silicon MacのGeekbech5データが出てる。倍、とかいうのは嘘じゃない、ということらしい。こっちにGeekbench Browserから拾ってくれてるのをみると、こないだ買い換えたばかりのMacBook Pro 13" 4ports 2GHzに対して、Single Coreで3割増し、Multi Coreで5割増しになっている。Geekbenchの3.2GHzというクロック計算が正しいとすると、性能の違いはほぼ平均クロック比ということになる。Compute Scoreでは倍を超えていて、Compute Scoreが高くなるということは高性能側のCoreのL2 Cacheが12MBなのが効いてるということなんかな。
やっぱりSingle CoreのInstruction per clockはIntelと同じようなものということなんじゃないだろうか。ARMだからというよりはIntelのレガシーがなくてそのぶん面積が減ってるということだろうな。クロックはTSMCのプロセスルールが効いてるということかな。Geekbenchがクロック計算をどうやってるのか知らないけど。
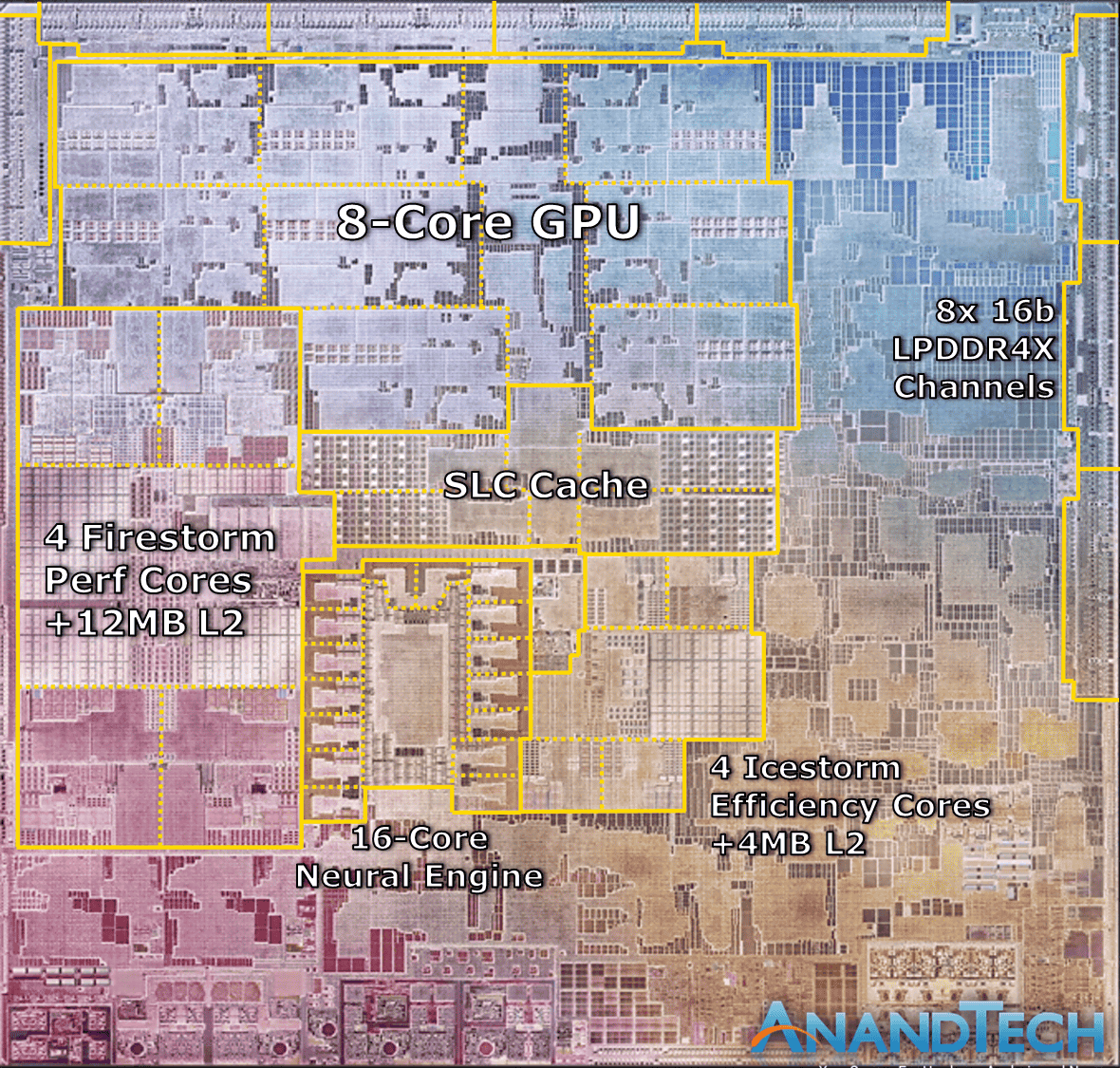
SingleよりMulti Coreの性能の向上率が高いということは、Hyper Threadingで遊んでるユニットを使い回すのより、独立した高効率Coreのほうが性能に寄与できるということかな。いくら低性能と言ってもCoreを増やすほうが面積は増えるので良し悪しだよな。高効率Coreと高性能Coreの何が違うのかよくわからないけど。たぶんベクタユニットの有無はあるよな。不動小数点演算も高効率側にはないかもしれない。チップの光学顕微鏡写真を見るとCore面積は3:1ぐらいの違いがあるので、高効率側はいろんなものがなさそうで、いろいろマイクロコードになっていそう。でもイベントで出たチップ構成の絵と全然違うがな。
Unified memoryとか言ってるけど、やっぱりインターフェイスは普通の128ビットバスのLPDDR4Xなんだ。バスが同じで配線距離がそんなに効くのかな。電気設計は楽だろうけど。SLC Cacheがまんなかに配置されてて、CPU、GPU、Neuroの全部で共通になってるということがunifiedなのかな。
え〜ん、3ヶ月早く出てくれてたら、というか古いMBPのバッテリがもう3ヶ月保ってくれてたらなあ。別にUSB-Cポートが4つじゃなきゃダメだったわけではなくて、価格対性能比で2portモデルより4portにしただけだったし。悲しい。
やっぱりSingle CoreのInstruction per clockはIntelと同じようなものということなんじゃないだろうか。ARMだからというよりはIntelのレガシーがなくてそのぶん面積が減ってるということだろうな。クロックはTSMCのプロセスルールが効いてるということかな。Geekbenchがクロック計算をどうやってるのか知らないけど。
SingleよりMulti Coreの性能の向上率が高いということは、Hyper Threadingで遊んでるユニットを使い回すのより、独立した高効率Coreのほうが性能に寄与できるということかな。いくら低性能と言ってもCoreを増やすほうが面積は増えるので良し悪しだよな。高効率Coreと高性能Coreの何が違うのかよくわからないけど。たぶんベクタユニットの有無はあるよな。不動小数点演算も高効率側にはないかもしれない。チップの光学顕微鏡写真を見るとCore面積は3:1ぐらいの違いがあるので、高効率側はいろんなものがなさそうで、いろいろマイクロコードになっていそう。でもイベントで出たチップ構成の絵と全然違うがな。
Unified memoryとか言ってるけど、やっぱりインターフェイスは普通の128ビットバスのLPDDR4Xなんだ。バスが同じで配線距離がそんなに効くのかな。電気設計は楽だろうけど。SLC Cacheがまんなかに配置されてて、CPU、GPU、Neuroの全部で共通になってるということがunifiedなのかな。
え〜ん、3ヶ月早く出てくれてたら、というか古いMBPのバッテリがもう3ヶ月保ってくれてたらなあ。別にUSB-Cポートが4つじゃなきゃダメだったわけではなくて、価格対性能比で2portモデルより4portにしただけだったし。悲しい。
Apple Silicon Mac [日常のあれやこれや]
Apple Silicon Mac出ちゃったなあ。これまで680x0→PowerPC→x86ときてARMということで、これで4つめ。毎回乗り越えてきた、というよりは、それ以前を捨ててきた、というほうが正しいかもしれない。こっちも慣れっこ、ちゃあ慣れっこなんだよな。まあ、これまでのシェアの少ない立場では既存ユーザを確保するより、新規ユーザを取り込める戦略を取ったほうが有利なので当然なのかもしれない。でもこれからは違うよな。
しかし、ARMに切り替えたことでそんなにパフォーマンスの差がでるかなあ。ずっと昔、PowerPCに切り替えたあと、G3ではCPUのキャッシュが効いて面積の小ささとコミで価格対性能比がぐっと上がってありがたかったけど、そのあと性能を上げようとするとパイプラインを深くしてマイクロコード化して分岐予測して、でどんどん複雑になってPowerPCのシンプルだというメリットが減って最終的に捨てることになった。
x86も古いぶん、レガシーな部分を引きずってるので不利ではあるだろうけど、PowerPCと同じようにARMだって同じ道を歩むような気がするけど。iPhoneが売れてるので数のメリットはあってTSMCに研究開発投資を促しやすいというのはあるだろうな。AppleがTSMCに直接投資するとかあるんだろうか。性能よりも結局、CPUのラインナップと価格を制御しやすいということなんだろうなあ。シングルコア性能が頭打ちになってもMac用にはコア数を増やす方向にするとか、GPUを盛るとか、I/O周りを取り込むとかあるだろうし。あ、I/Oはもう入っちゃってるのか。昔はADBとかTCP/IPスタックとか何でもかんでもソフトだったのに。
そういえばまたFatBinaryになるのか。/Libraryと/System/Libraryが膨れ上がるんだよなあ、あれ減らすのもめんどくさいし。Rosettaの切り捨てで悩んだのも、もう9年前のことか。忘れるのも速いな。「忘れようとしても思い出せない」というバカボンのパパの名言があったな。
高性能と低消費電力のコアを使い分けるのって、どうやってるんだろうか。最小単位はスレッドだろうから切り替えるたびにどっちに適しているスレッドかを、前回のスライスでのCPUの使い方から判断するのかな。スレッドスケジュールはKernelがやってるんだろうから、入出力の乗ったスレッドやUI用のスレッドは必ず低消費にまわすとかはするだろうな。発表ではぜんぶハードウェアでやっているような感じだったけどほんとかな。
128Kが1985年、PowerPC601が1994年、CoreDuoを積んだのが2006年なので、x86は長いほうなんだ。どんどん寿命が短くなってるような気がしたのは間違いで、やっぱり歳のせいか。そういえばx86の途中で32ビットモードの切り捨て、というのもあったので実際には刻みはもう1つあったと言ってもいいよな。16→32ビットは680x0でたまたまラッキー、だったんだけど僕はこれのおかげで当時9801を使っていた生産技術の連中が苦労してたメモリセグメントの問題を知らずに済んだ。僕はMac IIからの付き合いなので、もう33年にもなる。長いなあ。
ところで、「Secure Enclave」てなんだ?CPUの2+2コアぶんくらいのすごい面積食ってるけど。
しかし、ARMに切り替えたことでそんなにパフォーマンスの差がでるかなあ。ずっと昔、PowerPCに切り替えたあと、G3ではCPUのキャッシュが効いて面積の小ささとコミで価格対性能比がぐっと上がってありがたかったけど、そのあと性能を上げようとするとパイプラインを深くしてマイクロコード化して分岐予測して、でどんどん複雑になってPowerPCのシンプルだというメリットが減って最終的に捨てることになった。
x86も古いぶん、レガシーな部分を引きずってるので不利ではあるだろうけど、PowerPCと同じようにARMだって同じ道を歩むような気がするけど。iPhoneが売れてるので数のメリットはあってTSMCに研究開発投資を促しやすいというのはあるだろうな。AppleがTSMCに直接投資するとかあるんだろうか。性能よりも結局、CPUのラインナップと価格を制御しやすいということなんだろうなあ。シングルコア性能が頭打ちになってもMac用にはコア数を増やす方向にするとか、GPUを盛るとか、I/O周りを取り込むとかあるだろうし。あ、I/Oはもう入っちゃってるのか。昔はADBとかTCP/IPスタックとか何でもかんでもソフトだったのに。
そういえばまたFatBinaryになるのか。/Libraryと/System/Libraryが膨れ上がるんだよなあ、あれ減らすのもめんどくさいし。Rosettaの切り捨てで悩んだのも、もう9年前のことか。忘れるのも速いな。「忘れようとしても思い出せない」というバカボンのパパの名言があったな。
高性能と低消費電力のコアを使い分けるのって、どうやってるんだろうか。最小単位はスレッドだろうから切り替えるたびにどっちに適しているスレッドかを、前回のスライスでのCPUの使い方から判断するのかな。スレッドスケジュールはKernelがやってるんだろうから、入出力の乗ったスレッドやUI用のスレッドは必ず低消費にまわすとかはするだろうな。発表ではぜんぶハードウェアでやっているような感じだったけどほんとかな。
128Kが1985年、PowerPC601が1994年、CoreDuoを積んだのが2006年なので、x86は長いほうなんだ。どんどん寿命が短くなってるような気がしたのは間違いで、やっぱり歳のせいか。そういえばx86の途中で32ビットモードの切り捨て、というのもあったので実際には刻みはもう1つあったと言ってもいいよな。16→32ビットは680x0でたまたまラッキー、だったんだけど僕はこれのおかげで当時9801を使っていた生産技術の連中が苦労してたメモリセグメントの問題を知らずに済んだ。僕はMac IIからの付き合いなので、もう33年にもなる。長いなあ。
ところで、「Secure Enclave」てなんだ?CPUの2+2コアぶんくらいのすごい面積食ってるけど。
"Go To"キャンペーン [日常のあれやこれや]
"Go To"キャンペーンというのが始まったそうな。詳しくは知らないんだけど、きっとC言語で
また、特殊な処理として
いや、昼間っから暇なわけじゃないんだけど、つい、「Go To」と聞くとダイクストラ先生を思い出して、ね。
const int stayHome = -1;
for (unsigned i = 0 ; i < 0xFFFFFFFF ; i ++) {
if (i < 0)
goto tokyo; // ERROR!!
if (i % 0x1000 == 0x1001)
goto chiba; // OK
}
tokyo:
return(stayHome);
chiba:
bailout();
}
とか
#include <setjmp.h>
set_jump departedTokyo;
int main()
{
if (setjump(departedTokyo) == 0) { // ERROR!!
// ...
とかということだろうと思う。また、特殊な処理として
pthread_t alreadyBooking;
// ....
int date = pthread_cancel(alreadyBooking);
if (10 <= date && date <= 17)
return fee;
else
pthread_kill(alreadyBooking, SIGWASTEMONEY);
というのもあるらしい。いや、昼間っから暇なわけじゃないんだけど、つい、「Go To」と聞くとダイクストラ先生を思い出して、ね。
死んでません [日常のあれやこれや]
このブログを2007年から始めて、長くて震災時の数週間しか間をあけたことがなかったんだけど、今回は2ヶ月を超えた。このブログを見てくれていた皆さん、ジジイなせいでコロナで死んだか、と思ったかもしれませんが、残念、生きてます。
この4月後半から今の会社で「テレワーク」になってずっとうちに引きこもって仕事してた。出社しないとこれまで通勤に費やしていたほぼ1日に2時間半が自由な時間として手に入ったので、低プライオリティでやろうと思っていたことをこの時間を使ってやろうと思った。うちには光学定盤はないのでやりたいと思っている実験はできないけど、計算ならできる。ということで、20年近く前の昔、光ディスク用のレンズをやってた頃、できるのではないか、と思いながら忙しくてできなかった計算を思い出してやることにした。
やり始めていきなり進捗があって、20年前のもやもやが解決した。やったじゃん、その後いくつかの拡張が思った通りに解決して、そのたびに会社にレポートとして報告をあげた。他のみんなにはどこがすごいのかわからん、なんて言われたけど、ひとりで盛り上がって日中ずっと計算を続ける、というのをこれ、発表したらみんなぶっ飛ぶぞ、と思いながらほぼ2ヶ月続けてきた。ずっとほとんどランナーズハイ状態になってた。
計算と並行して同じことをやってる人はいないか、とGoogle scholarページを徘徊して回った。前の会社では論文入手に金を払うという意識がなかった。それは部署が多くあって経費としては薄まってただけで、ちゃんと必要な対価を払っていたんだけど、今の会社ではそういうわけにはいかない。限りなく黒に近いグレーだけど手に入らない論文はSci-Hubの生き残りサイトのお世話になった。さすがに2019年以降の新しい論文はロハでは手に入らない。しかし僕が探す限り同じようなことをしてるのは見当たらなかった。これはひょっとしてやったんではないか、と思っていた。
はじめのアイデアを拡張し続けて、先日かなり一般化された表現にたどり着いてひと段落だと思った。同じような結論を得ている論文は見当たらなかった。いくつか、より一般化された表現とか、計算手法とかに言及しているものがあったけど、僕が見る限り「帯短たすき長」という感じだった。さて、どこに発表しようか、と思い悩んでいた。
ところが先日、その一般化された表現の式をいじっていて、あることに気がついた。僕がたどり着いた式が実はもう70年も前の、ある非常に有名な論文に載っている式と、表現は違ってるけど物理的には等価だということが分かった。出発点は違ってるんだけど、結論は同じになったということで、まあ、やりたいことは同じなので最終的に同じになるというのは、別の登山口から山に登るようなもので全然あることだろう。でもさすがに僕はショックで真っ青になった。僕の悪い癖である「車輪の再発明」を2ヶ月かけてやってしまった、ということだった。
僕はたどり着いた式に従って数値計算できるコードも書いた。これに関係する普通の人はZemaxやCodeVなんかの最適化ソフトウェアを使うけど、僕のコードはそれとは無関係にもっと手っ取り早く、というかどんな条件でも100msecで、しかも最適化よりずっといい結果を得ることができる。
なんでみんな70年も前に結論された式を使ってないんだ?僕は2ヶ月もかかったけど、それを知ってれば誰でもできるじゃん。なんで誰もやってないの?それともみんなやってて僕が知らないだけだったの?前の会社ではこれを仕事にしてるひとは僕以外にもいたけど、誰も使ってなかった。みんながやってれば僕は「車輪の再発明」を2ヶ月もかけてやらずにすんだはずなのに。なんで???
わからん。「車輪の再発明」は論文にはならないけど、別の何らかの方法でおおやけにして専門家の評価を仰ぎたい。専門家からは「ゴミだ」と言われるのかも知れない。じゃあなんでお前らこれをやらないの?ほんとにわからん。
ずっと一人でランナーズハイ状態からどん底に落ちた感じで、ちょっと、気持ちが落ち着くまで時間がかかる。
この4月後半から今の会社で「テレワーク」になってずっとうちに引きこもって仕事してた。出社しないとこれまで通勤に費やしていたほぼ1日に2時間半が自由な時間として手に入ったので、低プライオリティでやろうと思っていたことをこの時間を使ってやろうと思った。うちには光学定盤はないのでやりたいと思っている実験はできないけど、計算ならできる。ということで、20年近く前の昔、光ディスク用のレンズをやってた頃、できるのではないか、と思いながら忙しくてできなかった計算を思い出してやることにした。
やり始めていきなり進捗があって、20年前のもやもやが解決した。やったじゃん、その後いくつかの拡張が思った通りに解決して、そのたびに会社にレポートとして報告をあげた。他のみんなにはどこがすごいのかわからん、なんて言われたけど、ひとりで盛り上がって日中ずっと計算を続ける、というのをこれ、発表したらみんなぶっ飛ぶぞ、と思いながらほぼ2ヶ月続けてきた。ずっとほとんどランナーズハイ状態になってた。
計算と並行して同じことをやってる人はいないか、とGoogle scholarページを徘徊して回った。前の会社では論文入手に金を払うという意識がなかった。それは部署が多くあって経費としては薄まってただけで、ちゃんと必要な対価を払っていたんだけど、今の会社ではそういうわけにはいかない。限りなく黒に近いグレーだけど手に入らない論文はSci-Hubの生き残りサイトのお世話になった。さすがに2019年以降の新しい論文はロハでは手に入らない。しかし僕が探す限り同じようなことをしてるのは見当たらなかった。これはひょっとしてやったんではないか、と思っていた。
はじめのアイデアを拡張し続けて、先日かなり一般化された表現にたどり着いてひと段落だと思った。同じような結論を得ている論文は見当たらなかった。いくつか、より一般化された表現とか、計算手法とかに言及しているものがあったけど、僕が見る限り「帯短たすき長」という感じだった。さて、どこに発表しようか、と思い悩んでいた。
ところが先日、その一般化された表現の式をいじっていて、あることに気がついた。僕がたどり着いた式が実はもう70年も前の、ある非常に有名な論文に載っている式と、表現は違ってるけど物理的には等価だということが分かった。出発点は違ってるんだけど、結論は同じになったということで、まあ、やりたいことは同じなので最終的に同じになるというのは、別の登山口から山に登るようなもので全然あることだろう。でもさすがに僕はショックで真っ青になった。僕の悪い癖である「車輪の再発明」を2ヶ月かけてやってしまった、ということだった。
僕はたどり着いた式に従って数値計算できるコードも書いた。これに関係する普通の人はZemaxやCodeVなんかの最適化ソフトウェアを使うけど、僕のコードはそれとは無関係にもっと手っ取り早く、というかどんな条件でも100msecで、しかも最適化よりずっといい結果を得ることができる。
なんでみんな70年も前に結論された式を使ってないんだ?僕は2ヶ月もかかったけど、それを知ってれば誰でもできるじゃん。なんで誰もやってないの?それともみんなやってて僕が知らないだけだったの?前の会社ではこれを仕事にしてるひとは僕以外にもいたけど、誰も使ってなかった。みんながやってれば僕は「車輪の再発明」を2ヶ月もかけてやらずにすんだはずなのに。なんで???
わからん。「車輪の再発明」は論文にはならないけど、別の何らかの方法でおおやけにして専門家の評価を仰ぎたい。専門家からは「ゴミだ」と言われるのかも知れない。じゃあなんでお前らこれをやらないの?ほんとにわからん。
ずっと一人でランナーズハイ状態からどん底に落ちた感じで、ちょっと、気持ちが落ち着くまで時間がかかる。
「ばびぶべぼ」ゲーム [日常のあれやこれや]
さっきNHKの「チコちゃんに叱られる」を見ていたら、カラスのキョエちゃんが「ばびぶべぼゲーム」というのをやっていた。日本語の子音をすべて「B」に変えて発音してそれがなにか当てる、と言うゲーム。
「びぼびゃんび、びばばべぶ」→「チコちゃんに叱られる」
というもの。情報が欠落するハッシュ関数の値からもとの文を再構築するという問題。情報理論的には不可能なので「推論」でしかないが、ボキャブラリの特性や文法を援用すると可能性は上がる。ところで、この変換では「ん」は不動点になるので「ん」が多いとわかりやすくなる。準同型の単位元。
このゲームは「反ゲーム」もあり得て「あかさたなゲーム」は
「ちゃかちゃんな、しゃかららら」
文字にするとわかりにくい。「まじゃなさらたわからなかあ」
当然、「ばびぶべぼ」ゲームは「B」でなくてもいい。
「きこきゃんき、きかかけく」「にのにゃんに、にななねぬ」
同じように「あかさたな」ゲームは「あ」段でなくてもいい。
「ちょこちょんの、しょころろろ」「ちぇけちぇんね、しぇけれれれ」
なんか筒井康隆みたいになる。文字で読むとなんだかわからないけど、発音すると案外分かるのはなんでだろ。イントネーションが追加情報になるからか。日本語が情報伝達の手段としては冗長性が高い、ということなんだろうな。
他の言語でこういうゲームはどうなんだろうか。英語では子音で終わる単語があるのでそもそも置き換えが難しかったりするよな。イタリア語とかではどうなんだろ。
ところで、一人で発音してると「どうしたの、お父さん!?」と家人に横から突っ込まれる。面白いと我を忘れるので気を付けないといけない。
「びぼびゃんび、びばばべぶ」→「チコちゃんに叱られる」
というもの。情報が欠落するハッシュ関数の値からもとの文を再構築するという問題。情報理論的には不可能なので「推論」でしかないが、ボキャブラリの特性や文法を援用すると可能性は上がる。ところで、この変換では「ん」は不動点になるので「ん」が多いとわかりやすくなる。準同型の単位元。
このゲームは「反ゲーム」もあり得て「あかさたなゲーム」は
「ちゃかちゃんな、しゃかららら」
文字にするとわかりにくい。「まじゃなさらたわからなかあ」
当然、「ばびぶべぼ」ゲームは「B」でなくてもいい。
「きこきゃんき、きかかけく」「にのにゃんに、にななねぬ」
同じように「あかさたな」ゲームは「あ」段でなくてもいい。
「ちょこちょんの、しょころろろ」「ちぇけちぇんね、しぇけれれれ」
なんか筒井康隆みたいになる。文字で読むとなんだかわからないけど、発音すると案外分かるのはなんでだろ。イントネーションが追加情報になるからか。日本語が情報伝達の手段としては冗長性が高い、ということなんだろうな。
他の言語でこういうゲームはどうなんだろうか。英語では子音で終わる単語があるのでそもそも置き換えが難しかったりするよな。イタリア語とかではどうなんだろ。
ところで、一人で発音してると「どうしたの、お父さん!?」と家人に横から突っ込まれる。面白いと我を忘れるので気を付けないといけない。


{kind=link}