Apple Silicon MacのFirestormコア [日常のあれやこれや]
ここを経由してここ を教えてもらった。そこにApple M1 SoCの高性能側のコアであるFirestormのブロックダイアグラムがあって、なかなか面白い。
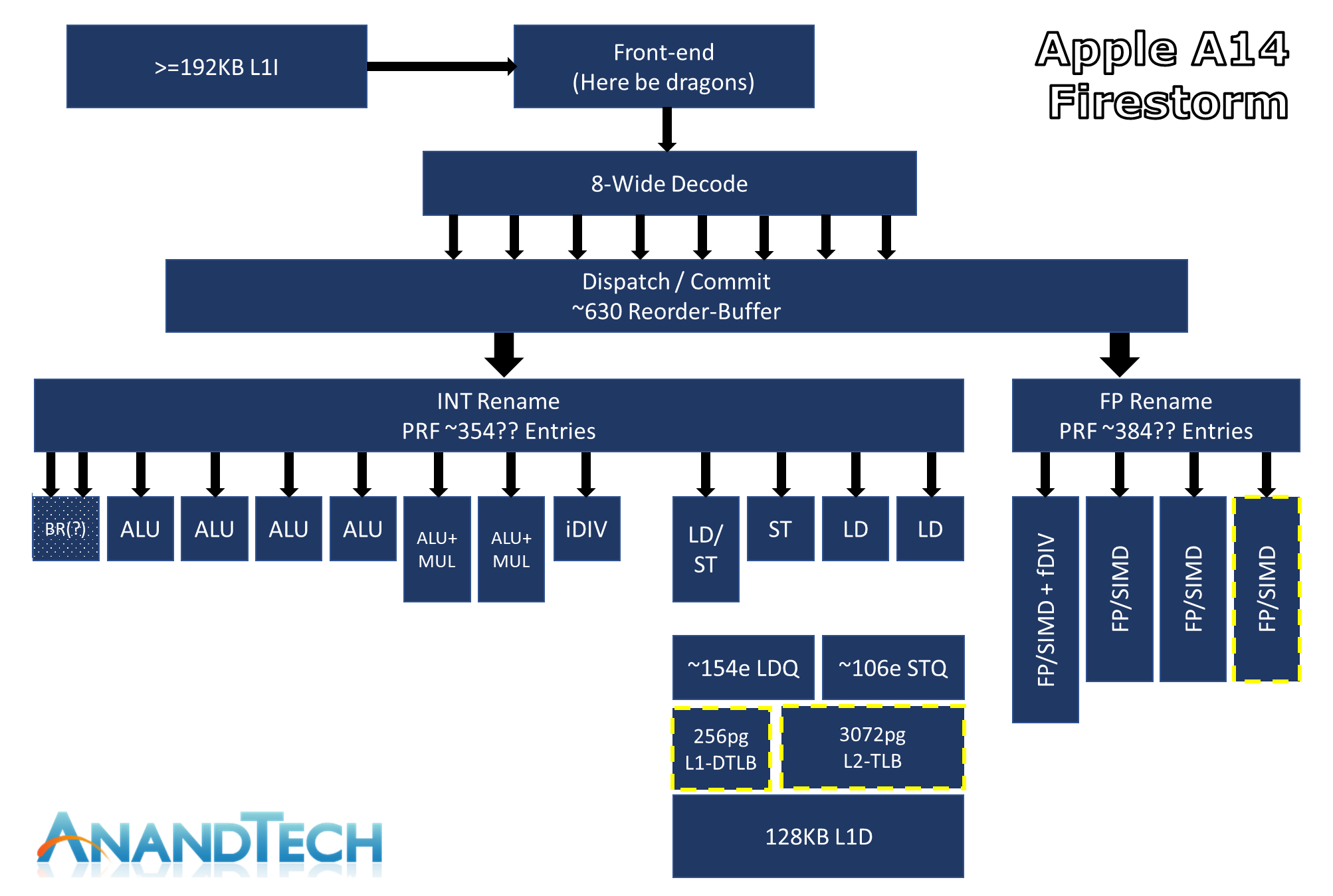 これだと8命令を同時にデコードできて、デコードした630個の命令の中から実行可能な命令を選び出せ(ディスパッチ)て、レジスタ名付け替え(Out-of-Order実行のキモの機構)が整数用に354エントリ浮動小数点用に384エントリあって、整数ALUが7つと分岐専用(?)ユニットがひとつ、そのうち整数の掛け算ができるのが2つと割り算までできるのが1つ(それ以外のALUはマイクロコードで実行か)、浮動小数点とベクタ演算のユニット(64ビット命令セットではスカラ浮動小数点もSIMDユニットが受け持つらしい。たしかに浮動小数点演算はヘビーでレイテンシも深くなりがちなのでALUに持たない方が簡単だな)が4つ、ロード/ストアユニットが4つとそれ用の深さ100以上のキューがそれぞれひとつずつ、それに192Kの命令用L1キャッシュと128Kのデータ用L1キャッシュと、L2キャッシュ用のTLBが3072ページぶんある(L2はコアに共通だったと思ったけど、それぞれTLBを持っててカチ合わないんだっけ?)、と描いてある。どこまでほんとなのかよくわからないけど、ディスパッチユニットのウィンドウサイズを測定したらしいデータを載せているので、そこそこ自信があるらしい。
これだと8命令を同時にデコードできて、デコードした630個の命令の中から実行可能な命令を選び出せ(ディスパッチ)て、レジスタ名付け替え(Out-of-Order実行のキモの機構)が整数用に354エントリ浮動小数点用に384エントリあって、整数ALUが7つと分岐専用(?)ユニットがひとつ、そのうち整数の掛け算ができるのが2つと割り算までできるのが1つ(それ以外のALUはマイクロコードで実行か)、浮動小数点とベクタ演算のユニット(64ビット命令セットではスカラ浮動小数点もSIMDユニットが受け持つらしい。たしかに浮動小数点演算はヘビーでレイテンシも深くなりがちなのでALUに持たない方が簡単だな)が4つ、ロード/ストアユニットが4つとそれ用の深さ100以上のキューがそれぞれひとつずつ、それに192Kの命令用L1キャッシュと128Kのデータ用L1キャッシュと、L2キャッシュ用のTLBが3072ページぶんある(L2はコアに共通だったと思ったけど、それぞれTLBを持っててカチ合わないんだっけ?)、と描いてある。どこまでほんとなのかよくわからないけど、ディスパッチユニットのウィンドウサイズを測定したらしいデータを載せているので、そこそこ自信があるらしい。
ARMの32ビットモードは歴史を抱えてて結構複雑になってるので、やっぱり32ビット命令は無視してデコードユニットを軽くして、そのぶんALUの数を増やしたんだろうなあ。ベクタレジスタは128ビット幅なのでx64の半分だけど、浮動小数点/SIMDユニットが4つとレジスタリネームが384エントリもあってそれが4コアあるので、FFTとかサイズ次第では爆速じゃないかなあ。
ALUはx64とARMで実質的に同じことをすればいいんだけど、こう見るとx64は命令長が可変だというだけですごく不利のような気がしてくる。M1みたいに古い命令はサポートしない、みたいなことはできなくて「自分の過去は全て責任を持つ」でないといけないのでよけい厳しいよなあ。
ユニットのレイテンシの違いや分岐命令でストールしたり、整数演算とSIMDがバランスよく並ぶなんてこともないだろうから、全部のALUとFP/SIMDユニットがいつも動いてるなんてことはないだろうけど、FirestormのInstructions per Clockのスループットは最大8命令ということで、これだとクロック同じでコア数同じでも性能5割増しとか十分あり得そうだよなあ。
LLVMコンパイラもAppleが仕切ってるわけだから、ハードウェアサポートしたくない命令を吐かないようにしてしまえばいいわけで、ARMの実行効率に寄与しない部分は全部剥ぎ取ることができる。Appleはやろうと思えばバリバリ筋肉質のコアにできる、ということだな。IntelやAMDに言わせれば「ずるい」ということになるけど。
なんか、買ったばかりのMacbook Proが、ぜんぜん使ってないところに電気を食ってるんじゃないかと思えてくるよなあ。
ARMの32ビットモードは歴史を抱えてて結構複雑になってるので、やっぱり32ビット命令は無視してデコードユニットを軽くして、そのぶんALUの数を増やしたんだろうなあ。ベクタレジスタは128ビット幅なのでx64の半分だけど、浮動小数点/SIMDユニットが4つとレジスタリネームが384エントリもあってそれが4コアあるので、FFTとかサイズ次第では爆速じゃないかなあ。
ALUはx64とARMで実質的に同じことをすればいいんだけど、こう見るとx64は命令長が可変だというだけですごく不利のような気がしてくる。M1みたいに古い命令はサポートしない、みたいなことはできなくて「自分の過去は全て責任を持つ」でないといけないのでよけい厳しいよなあ。
ユニットのレイテンシの違いや分岐命令でストールしたり、整数演算とSIMDがバランスよく並ぶなんてこともないだろうから、全部のALUとFP/SIMDユニットがいつも動いてるなんてことはないだろうけど、FirestormのInstructions per Clockのスループットは最大8命令ということで、これだとクロック同じでコア数同じでも性能5割増しとか十分あり得そうだよなあ。
LLVMコンパイラもAppleが仕切ってるわけだから、ハードウェアサポートしたくない命令を吐かないようにしてしまえばいいわけで、ARMの実行効率に寄与しない部分は全部剥ぎ取ることができる。Appleはやろうと思えばバリバリ筋肉質のコアにできる、ということだな。IntelやAMDに言わせれば「ずるい」ということになるけど。
なんか、買ったばかりのMacbook Proが、ぜんぜん使ってないところに電気を食ってるんじゃないかと思えてくるよなあ。
仕事で困ってること [日常のあれやこれや]
実は、僕はちょうど3年前、ある有名なレンズ設計用ソフトの営業とケンカしてそのソフトが使えなくなっていた(そんなの、いらねいやい!と、メールで啖呵を切った。「酸っぱいぶどう」そのまんまやがな)。ところが最近お客さんからその「レンズ設計用ソフト」で読めるデータをよこせと言われることがある。そのソフトの機能で、中身は読めないけど光線追跡したり、他の光学系の中に組み込んだりできる「ブラックボックス」というのがあって、そのデータを要求されるようになった。
昔だったら、ごめんなさい出せません、必要な計算はこちらでします、と言ったんだけど、最近それが通用しなくなってきた。データが出せないというと
特に米国では、光学素子のメーカは「ブラックボックス」にもなっていないナマのデータを提示するところも増えている。ガラスプレスの回折限界単玉非球面レンズなどは、設計よりも作る方がずっと難しいので、顧客の要求に答えられるところは積極的にそうしよう、ということだろう。
どうせ僕は多群ズームなんかの設計はしなくて、レンズ設計といっても仕事で必要なのはせいぜいガラスやプラの単玉非球面レンズで、それ以外は「レンズ設計ソフトウェア」の最適化ではできない、あるいは効率の悪い設計で、それがある意味僕のニッチでもある。従って汎用ソフトがないならないでそれほど困らない。そうでなければあとは汎用のエレメントを組み合わせるだけなので、光線追跡して評価ができれば十分である。
それにきっとソフトの営業では僕がブラックリストに入ってるだろうし。いや、もういちどライセンス受けたいといえば、ニコニコしながら売ってくれるだろうけど、それって、よけい悔しいなあ。ニコニコの顔の下に「ざまあ」と大書きしてあるようなもんだよなあ。
しかしすぐに
困ったなあ。
昔だったら、ごめんなさい出せません、必要な計算はこちらでします、と言ったんだけど、最近それが通用しなくなってきた。データが出せないというと
客:「では、どうやって設計したんだ?」 僕:「自分で書いて...」 客:「(なんだ素人か...)」という反応をされることが増えた。このエレメントの設計に最適化による収束計算は必要ない、と説明してもこれでたいていのお客さんはこれで話は終わり、という姿勢になる。
特に米国では、光学素子のメーカは「ブラックボックス」にもなっていないナマのデータを提示するところも増えている。ガラスプレスの回折限界単玉非球面レンズなどは、設計よりも作る方がずっと難しいので、顧客の要求に答えられるところは積極的にそうしよう、ということだろう。
どうせ僕は多群ズームなんかの設計はしなくて、レンズ設計といっても仕事で必要なのはせいぜいガラスやプラの単玉非球面レンズで、それ以外は「レンズ設計ソフトウェア」の最適化ではできない、あるいは効率の悪い設計で、それがある意味僕のニッチでもある。従って汎用ソフトがないならないでそれほど困らない。そうでなければあとは汎用のエレメントを組み合わせるだけなので、光線追跡して評価ができれば十分である。
それにきっとソフトの営業では僕がブラックリストに入ってるだろうし。いや、もういちどライセンス受けたいといえば、ニコニコしながら売ってくれるだろうけど、それって、よけい悔しいなあ。ニコニコの顔の下に「ざまあ」と大書きしてあるようなもんだよなあ。
しかしすぐに
社長&営業:「なんで客先に必要なデータが出せないんだ?」 僕: 「ソフトの営業と喧嘩しまして」なんてことになって、そうなると馬鹿野郎呼ばわり間違い無いよな。ごまかしててもすぐバレるよな。そもそもここにこうやって書いたらおしまいだもんな。
困ったなあ。
ジェネリクスとプロトコルなど [Swiftプログラミング]
個人的にちょっと困ったことが起きている。でも僕が何かして解決する内容ではないので、とりあえず頭を低くしてやり過ごすのを待つことにしてる。それですめばいいんだけど。
ところで全然話は違うけど、Swiftで書いててまたよくわからないことができた。こんどはジェネリクス....
ところで全然話は違うけど、Swiftで書いててまたよくわからないことができた。こんどはジェネリクス....
共用型の比較 [Swiftプログラミング]
勉強と慣れをかねてObjective-CをやめてSwiftでいろいろ書いてる。今日書いてて、Swiftのassociated valueつきのenumについて、ふとわからないことができた。誰か教えて....
YouTubeで聴くショスタコーヴィチ その5「森の歌」のどこが特別なのか [クラシック]
前回の続きでYouTubeにあるショスタコーヴィチを聴きながら、「社会主義リアリズム」に沿った作品を書くことになったふたつの事件とその周辺の話の最終回。
彼の「社会主義リアリズム」に沿った作品の頂点としての「森の歌」が、僕にはただそれだけではない「特別な作品」と思える、その理由について。今回はちょっと文字ばっかりが続くけど....
彼の「社会主義リアリズム」に沿った作品の頂点としての「森の歌」が、僕にはただそれだけではない「特別な作品」と思える、その理由について。今回はちょっと文字ばっかりが続くけど....
Apple Silicon Macのベンチマーク [日常のあれやこれや]
Apple Silicon MacのGeekbech5データが出てる。倍、とかいうのは嘘じゃない、ということらしい。こっちにGeekbench Browserから拾ってくれてるのをみると、こないだ買い換えたばかりのMacBook Pro 13" 4ports 2GHzに対して、Single Coreで3割増し、Multi Coreで5割増しになっている。Geekbenchの3.2GHzというクロック計算が正しいとすると、性能の違いはほぼ平均クロック比ということになる。Compute Scoreでは倍を超えていて、Compute Scoreが高くなるということは高性能側のCoreのL2 Cacheが12MBなのが効いてるということなんかな。
やっぱりSingle CoreのInstruction per clockはIntelと同じようなものということなんじゃないだろうか。ARMだからというよりはIntelのレガシーがなくてそのぶん面積が減ってるということだろうな。クロックはTSMCのプロセスルールが効いてるということかな。Geekbenchがクロック計算をどうやってるのか知らないけど。
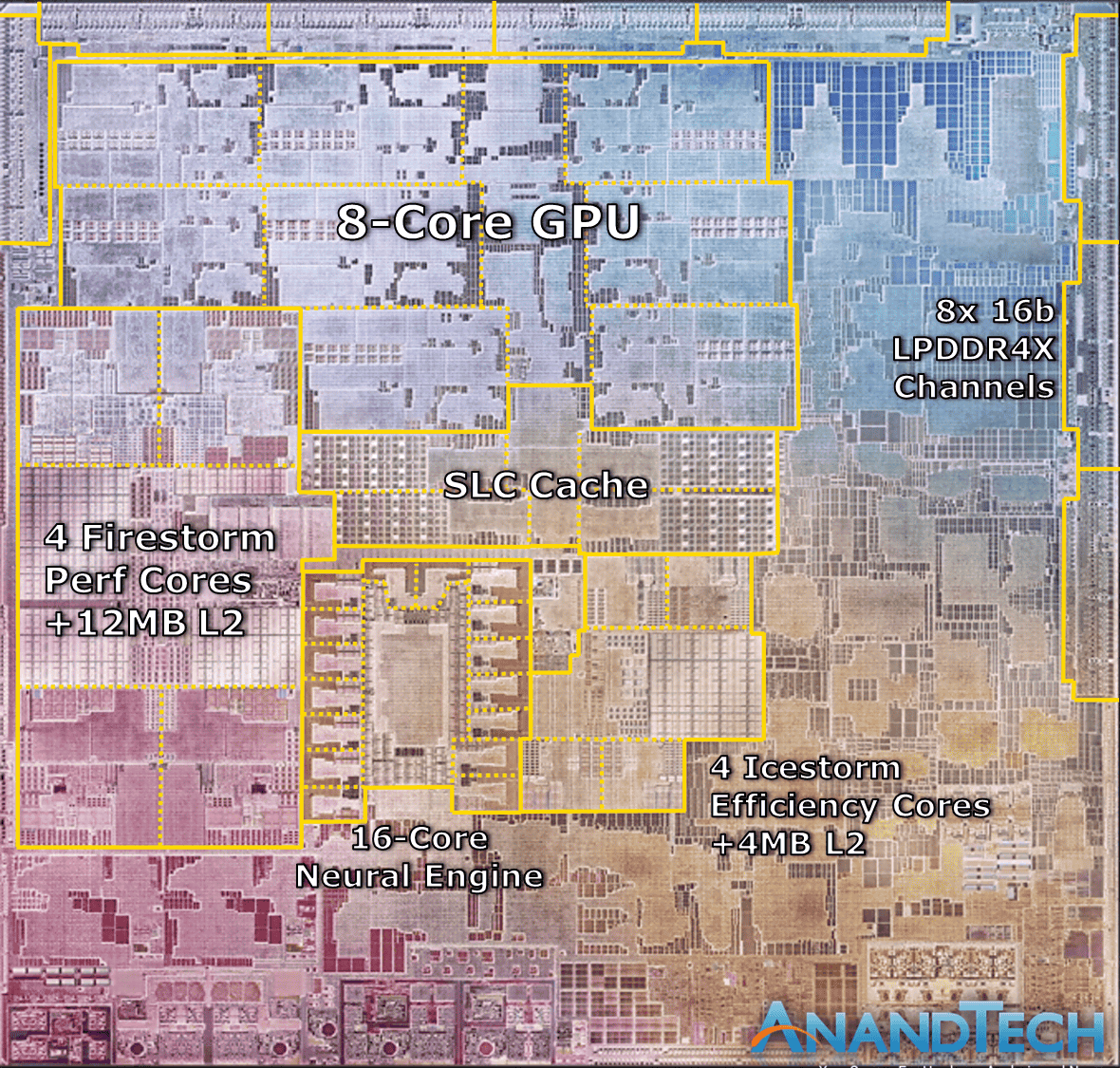
SingleよりMulti Coreの性能の向上率が高いということは、Hyper Threadingで遊んでるユニットを使い回すのより、独立した高効率Coreのほうが性能に寄与できるということかな。いくら低性能と言ってもCoreを増やすほうが面積は増えるので良し悪しだよな。高効率Coreと高性能Coreの何が違うのかよくわからないけど。たぶんベクタユニットの有無はあるよな。不動小数点演算も高効率側にはないかもしれない。チップの光学顕微鏡写真を見るとCore面積は3:1ぐらいの違いがあるので、高効率側はいろんなものがなさそうで、いろいろマイクロコードになっていそう。でもイベントで出たチップ構成の絵と全然違うがな。
Unified memoryとか言ってるけど、やっぱりインターフェイスは普通の128ビットバスのLPDDR4Xなんだ。バスが同じで配線距離がそんなに効くのかな。電気設計は楽だろうけど。SLC Cacheがまんなかに配置されてて、CPU、GPU、Neuroの全部で共通になってるということがunifiedなのかな。
え〜ん、3ヶ月早く出てくれてたら、というか古いMBPのバッテリがもう3ヶ月保ってくれてたらなあ。別にUSB-Cポートが4つじゃなきゃダメだったわけではなくて、価格対性能比で2portモデルより4portにしただけだったし。悲しい。
やっぱりSingle CoreのInstruction per clockはIntelと同じようなものということなんじゃないだろうか。ARMだからというよりはIntelのレガシーがなくてそのぶん面積が減ってるということだろうな。クロックはTSMCのプロセスルールが効いてるということかな。Geekbenchがクロック計算をどうやってるのか知らないけど。
SingleよりMulti Coreの性能の向上率が高いということは、Hyper Threadingで遊んでるユニットを使い回すのより、独立した高効率Coreのほうが性能に寄与できるということかな。いくら低性能と言ってもCoreを増やすほうが面積は増えるので良し悪しだよな。高効率Coreと高性能Coreの何が違うのかよくわからないけど。たぶんベクタユニットの有無はあるよな。不動小数点演算も高効率側にはないかもしれない。チップの光学顕微鏡写真を見るとCore面積は3:1ぐらいの違いがあるので、高効率側はいろんなものがなさそうで、いろいろマイクロコードになっていそう。でもイベントで出たチップ構成の絵と全然違うがな。
Unified memoryとか言ってるけど、やっぱりインターフェイスは普通の128ビットバスのLPDDR4Xなんだ。バスが同じで配線距離がそんなに効くのかな。電気設計は楽だろうけど。SLC Cacheがまんなかに配置されてて、CPU、GPU、Neuroの全部で共通になってるということがunifiedなのかな。
え〜ん、3ヶ月早く出てくれてたら、というか古いMBPのバッテリがもう3ヶ月保ってくれてたらなあ。別にUSB-Cポートが4つじゃなきゃダメだったわけではなくて、価格対性能比で2portモデルより4portにしただけだったし。悲しい。
Apple Silicon Mac [日常のあれやこれや]
Apple Silicon Mac出ちゃったなあ。これまで680x0→PowerPC→x86ときてARMということで、これで4つめ。毎回乗り越えてきた、というよりは、それ以前を捨ててきた、というほうが正しいかもしれない。こっちも慣れっこ、ちゃあ慣れっこなんだよな。まあ、これまでのシェアの少ない立場では既存ユーザを確保するより、新規ユーザを取り込める戦略を取ったほうが有利なので当然なのかもしれない。でもこれからは違うよな。
しかし、ARMに切り替えたことでそんなにパフォーマンスの差がでるかなあ。ずっと昔、PowerPCに切り替えたあと、G3ではCPUのキャッシュが効いて面積の小ささとコミで価格対性能比がぐっと上がってありがたかったけど、そのあと性能を上げようとするとパイプラインを深くしてマイクロコード化して分岐予測して、でどんどん複雑になってPowerPCのシンプルだというメリットが減って最終的に捨てることになった。
x86も古いぶん、レガシーな部分を引きずってるので不利ではあるだろうけど、PowerPCと同じようにARMだって同じ道を歩むような気がするけど。iPhoneが売れてるので数のメリットはあってTSMCに研究開発投資を促しやすいというのはあるだろうな。AppleがTSMCに直接投資するとかあるんだろうか。性能よりも結局、CPUのラインナップと価格を制御しやすいということなんだろうなあ。シングルコア性能が頭打ちになってもMac用にはコア数を増やす方向にするとか、GPUを盛るとか、I/O周りを取り込むとかあるだろうし。あ、I/Oはもう入っちゃってるのか。昔はADBとかTCP/IPスタックとか何でもかんでもソフトだったのに。
そういえばまたFatBinaryになるのか。/Libraryと/System/Libraryが膨れ上がるんだよなあ、あれ減らすのもめんどくさいし。Rosettaの切り捨てで悩んだのも、もう9年前のことか。忘れるのも速いな。「忘れようとしても思い出せない」というバカボンのパパの名言があったな。
高性能と低消費電力のコアを使い分けるのって、どうやってるんだろうか。最小単位はスレッドだろうから切り替えるたびにどっちに適しているスレッドかを、前回のスライスでのCPUの使い方から判断するのかな。スレッドスケジュールはKernelがやってるんだろうから、入出力の乗ったスレッドやUI用のスレッドは必ず低消費にまわすとかはするだろうな。発表ではぜんぶハードウェアでやっているような感じだったけどほんとかな。
128Kが1985年、PowerPC601が1994年、CoreDuoを積んだのが2006年なので、x86は長いほうなんだ。どんどん寿命が短くなってるような気がしたのは間違いで、やっぱり歳のせいか。そういえばx86の途中で32ビットモードの切り捨て、というのもあったので実際には刻みはもう1つあったと言ってもいいよな。16→32ビットは680x0でたまたまラッキー、だったんだけど僕はこれのおかげで当時9801を使っていた生産技術の連中が苦労してたメモリセグメントの問題を知らずに済んだ。僕はMac IIからの付き合いなので、もう33年にもなる。長いなあ。
ところで、「Secure Enclave」てなんだ?CPUの2+2コアぶんくらいのすごい面積食ってるけど。
しかし、ARMに切り替えたことでそんなにパフォーマンスの差がでるかなあ。ずっと昔、PowerPCに切り替えたあと、G3ではCPUのキャッシュが効いて面積の小ささとコミで価格対性能比がぐっと上がってありがたかったけど、そのあと性能を上げようとするとパイプラインを深くしてマイクロコード化して分岐予測して、でどんどん複雑になってPowerPCのシンプルだというメリットが減って最終的に捨てることになった。
x86も古いぶん、レガシーな部分を引きずってるので不利ではあるだろうけど、PowerPCと同じようにARMだって同じ道を歩むような気がするけど。iPhoneが売れてるので数のメリットはあってTSMCに研究開発投資を促しやすいというのはあるだろうな。AppleがTSMCに直接投資するとかあるんだろうか。性能よりも結局、CPUのラインナップと価格を制御しやすいということなんだろうなあ。シングルコア性能が頭打ちになってもMac用にはコア数を増やす方向にするとか、GPUを盛るとか、I/O周りを取り込むとかあるだろうし。あ、I/Oはもう入っちゃってるのか。昔はADBとかTCP/IPスタックとか何でもかんでもソフトだったのに。
そういえばまたFatBinaryになるのか。/Libraryと/System/Libraryが膨れ上がるんだよなあ、あれ減らすのもめんどくさいし。Rosettaの切り捨てで悩んだのも、もう9年前のことか。忘れるのも速いな。「忘れようとしても思い出せない」というバカボンのパパの名言があったな。
高性能と低消費電力のコアを使い分けるのって、どうやってるんだろうか。最小単位はスレッドだろうから切り替えるたびにどっちに適しているスレッドかを、前回のスライスでのCPUの使い方から判断するのかな。スレッドスケジュールはKernelがやってるんだろうから、入出力の乗ったスレッドやUI用のスレッドは必ず低消費にまわすとかはするだろうな。発表ではぜんぶハードウェアでやっているような感じだったけどほんとかな。
128Kが1985年、PowerPC601が1994年、CoreDuoを積んだのが2006年なので、x86は長いほうなんだ。どんどん寿命が短くなってるような気がしたのは間違いで、やっぱり歳のせいか。そういえばx86の途中で32ビットモードの切り捨て、というのもあったので実際には刻みはもう1つあったと言ってもいいよな。16→32ビットは680x0でたまたまラッキー、だったんだけど僕はこれのおかげで当時9801を使っていた生産技術の連中が苦労してたメモリセグメントの問題を知らずに済んだ。僕はMac IIからの付き合いなので、もう33年にもなる。長いなあ。
ところで、「Secure Enclave」てなんだ?CPUの2+2コアぶんくらいのすごい面積食ってるけど。
YouTubeで聴くショスタコーヴィチ その4「森の歌」続き [クラシック]
前回はショスタコーヴィチがジダーノフ批判を受けたあと、「森の歌」を作曲するに至ったエピソードを千葉潤 著「ショスタコーヴィチ」とhttp://www.shostakovich.ruから拾ってまとめてみた。「森の歌」は彼に対する「御用作曲家」のイメージを決定付けた曲で、「ベルリン陥落」をはじめとするその前後の映画音楽と同列に扱われることが多い。
しかし僕は、それはちょっと違う、と思っている。今日はその理由となる具体的な特徴を音符を交えてあげることにする....
しかし僕は、それはちょっと違う、と思っている。今日はその理由となる具体的な特徴を音符を交えてあげることにする....


{kind=link}